迭代器概念与traits编程技法
迭代器是一种smart pointer
我们为list设计一个迭代器,则有如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| tempalte <typename T>
class ListItem{
public:
T value()const{return _value;}
ListItem*next()const{return _next;}
...
private:
T _value;
ListItem*_next;
};
template <typename T>
class T{
public:
void insert_front(T value);
void insert_end(T value);
void display(std::ostream&os=std::cout)const;
private:
ListItem<T>*_end;
ListItem<T>*_front;
long _size;
};
template<class Item>
struct ListIter{
Item*ptr;
ListIter(Item*p=0):ptr(p){}
Item&operator*()const{return *ptr;}
Item*operator->()const{return *ptr;}
ListIter&operator++(){
ptr=ptr->next;
return *this;
}
ListIter operator++(int){
ListIter temp=*this;
++*this;
return temp;
}
bool operator==(const ListIter&i)const{
return ptr==i.ptr;
}
bool operator!=(const ListIter&i)const{
return ptr!=i.ptr;
}
}
void main(){
List<int>myList;
for(int i=0;i<5;++i){
myList.insert(i);
myList.insert(i+2);
}
myList.display();
ListIter<ListItem<int> > begin(myList.front());
ListIter<ListItem<int> > end;
ListIter<ListItem<int> > begin;
ListIter<ListItem<int> > iter;
iter=find(begin,end,3);
if(iter==end)
cout<<"not found"<<endl;
else
cout<<"found."<<iter->value()<<endl;
}
|
Traits编程技法
class template可以用来“萃取”迭代器的特性。
1
2
3
4
| template<class I>
struct iterator_traits{
typedef typename I::value_type value_type;
}
|
这个traits,其意义为,如果I定义有自己的value_type,那么通过这个traits的作用,萃取出来的value_type就是I::value_type。有
1
2
3
4
5
| template<class T>
typename iterator_traits<T>::value_type //返回值
func(I ite){
return *ite;
}
|
使用此种方法的好处是我们traits拥有一个特化版本
1
2
3
4
| template<class T>
struct iterator_traits<T*>{
typedef T value_type;
}
|
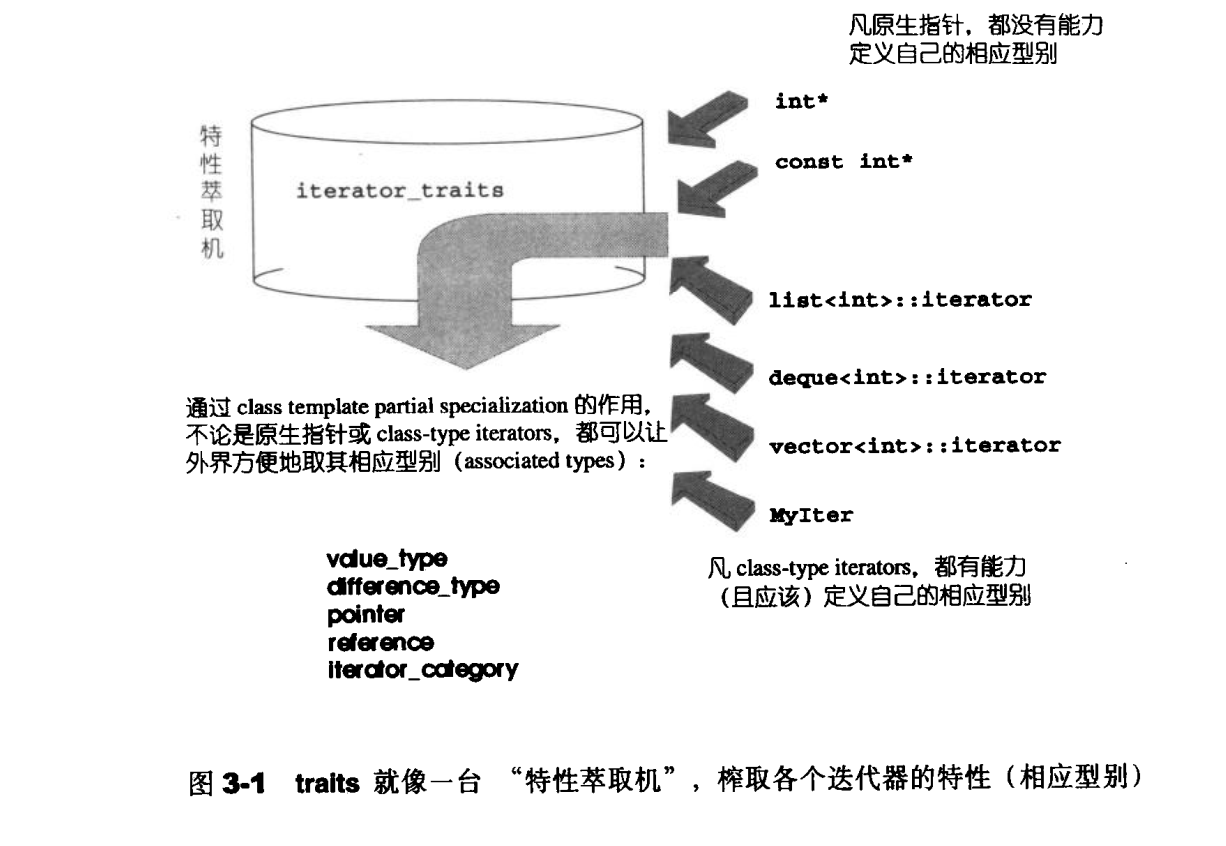
其中迭代器相应的型别有能以下五种:
1
2
3
4
5
| value type
difference type
pointer
reference
iterator catagoly
|
若想要与STL容器兼容,则需要定义这五种型别。
1
2
3
4
5
6
7
8
| template<class I>
struct iterator_traits{
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
}
|
迭代器型别之一:value type
value type是指迭代器所指对象的类别 。
迭代器型别之二: difference type
difference type为两个迭代器之间的距离,在STL中的count(),其传回值就必须要使用迭代器的difference type:
1
2
3
4
5
6
7
8
| template<class I,class T>
typename iterator_traits<I>::difference_type;
count(I first,I last,const T&value){
typename iterator_traits<I>::difference_type n=0;
for(;first!=last;++first)
if(*frist==value)++n;
return n;
}
|
迭代器型别之三:reference type
在C++中,函数要传回左值,以by reference方式进行,当p是个mutable iterators时,如果value type是T,那么*p的型别不就是T,则是T&。
迭代器型别之四:pointer type
现在我们把reference type和pointer type的这两个型别加入traits内,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| template<class I>
struct iterator_traits{
...
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};
template<class T>
struct iterator_traits<T*>{
...
typedef T*pointer;
typedef T& reference;
}
template<class T>
struct iterator_traits<const T*>{
...
typedef const T* pointer;
typedef const T& reference;
}
|
迭代器型别之五:iterator_category
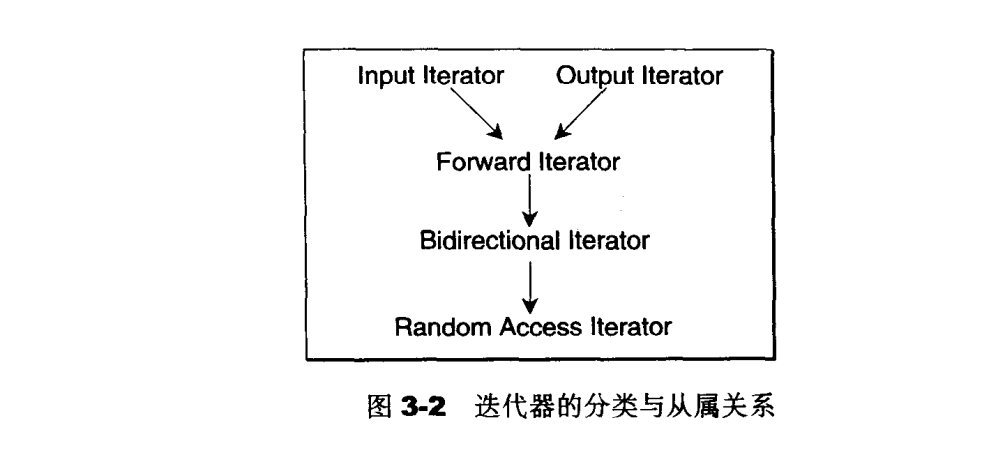
根据移动特性与施行操作,迭代器被分为五类:
- Input Iterator:这种迭代器所指的对象,不允许被外界改变,只读。
- Output Iterator:唯写。
- Forward Iterator:允许“写入型”算法(例如 replace())在此种迭代器所形成的区间上进行读写操作。
- Bidirectional Iterator:可双向移动,某些算法需要逆向走访某个迭代器区间(如逆向拷贝某范围内元素),可使用Bidirectional Iterators。
- Random Access Iterator:前四种迭代器都只供应一部分指针算术能力(前三种支持 operator++,第四种再加上operator—),第五种则涵盖所有指针算法能力,包括p+n,p-n,p[n],p1-p2,p1<p2。
拿advance()函数为例,该函数有两个参数,迭代器P和数据n,函数内部将p累进n次,下面有三份定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| template<class InputIterator,class Distance>
void advance_II(InputIterator&i,Distance n){
while(n--)++;
}
template<class BidirectionalIterator,class Distance>
void advance_BI(BidirectionalIterator&i,Distance n){
if(n>=0)
while(n--)++i;
else
while(n++)--i;
}
template<class RandomAccessIterator,class Distance>
void advance_RAI(RandomAccessIterator&i,Distance n){
i+=n;
}
template<class InputIterator,class Distance>
void advance(InputIterator&i,Distance n){
if(is_random_access_iterator(i))
advance_RAI(i,n);
else if(is_bidirectional_iterator(i))
advance_RI(i,n);
else
advance_IT(i,n);
}
|
如下为我们在在编译期就确定使用某个版本,运用重载函数机制来达到这个目标。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
struct input_iterator_tag{};
struct output_iterator_tag{};
struct forward_iterator_tag:public input_iterator_tag{};
struct bidirectional_iterator_tag:public forward_iterator_tag{};
struct random_access_iterator_tag:public bidirectional_iterator_tag{};
template<class InputIterator,class Distance>
inline void _advance(InputIterator&i,Distance n,input_iterator_tag){
while(n--)++i;
}
template<class ForwardIterator,class Distance>
inline void _advance(ForwardIterator&i,Distance n,forward_iterator_tag){
_advance(i,n,input_iterator_tag());
}
template<class BidiectionalIterator,class Distance>
inline void _advance(BidiectionalIterator&i,Distance n,bidirectional_iterator_tag){
if(n>=0)
while(n--)++i;
else
while(n++)--i;
}
template<class RandomAccessIterator,class Distance>
inline void _advance(RandomAccessIterator&i,Distance n,random_access_iterator_tag){
i+=n;
}
template<class InputIterator,class Distance>
inline void advance(InputIterator&i,Distance n){
_advance(i,n,iterator_traits<InputIterator>::iterator_category());
}
template<class T>
struct iterator_traits{
....
typedef typename I::iterator_category iterator_category;
}
|
我们可以通过继承来消除“单纯只做传递调用”的函数

std::iterator 的保证
以distance为例,我们使用消除“单纯只做传递调用”的函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| template<class InputIterator>
inline iterator_traits<InputIterator>::difference_type
_distance(InputIterator first,InputIterator last,input_iterator_tag){
iterator_traits<InputIterator>::difference_type n=0;
while(first!=last){
++first;
++n;
}
return n;
}
template<class RandomAccessIterator>
inline iterator_traits<RandomAccessIterator>::difference_type
_distance(RandomAccessIterator first,RandomAccessIterator last,random_access_iterator_tag){
return last-first;
}
template<class InputIterator>
inline iterator_traits<InputIterator>::difference_type
distance(InputIterator first,InputIterator last){
typedef typename iterator_traits<InputIterator>::iterator_category category;
return _distance(first,last,category());
}
|
STL提供了一个iterators class如下,如果每个新设计的迭代器都继承自它,则可保证符合STL所需规范。
1
2
3
4
5
6
7
8
9
10
11
12
13
| template<class Category,class T,class Distance=ptrdiff_t,class Pointer=T*,class Reference=T&>
struct iterator{
typedef Category iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef Pointer pointer;
typedef Reference reference;
}
template<class Item>
struct ListIter:public std::iterator<std::forwared_iterator_tag,Item>{
}
|
iterator源代码完整重列


序列式容器
vector容器
vector定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| template<class T,class Alloc=alloc>
class vector{
public:
typedef T value_type;
typedef value_type* pointer;
typedef value_type* iterator;
typedef value_type& reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
void push_back(const T&x){
if(finish!=end_of_storage){
construct(finish,x);
++finish;
}else
insert_aux(end(),x);
}
void pop_back(){
--finish;
destroy(finish);
}
iterator erase(iterator position){
if(position+1!=end()){
copy(position+1,finish,position);
--finish;
}
destory(finish);
return position;
}
private:
iterator start;
iterator finish;
iterator end_of_storage;
}
|
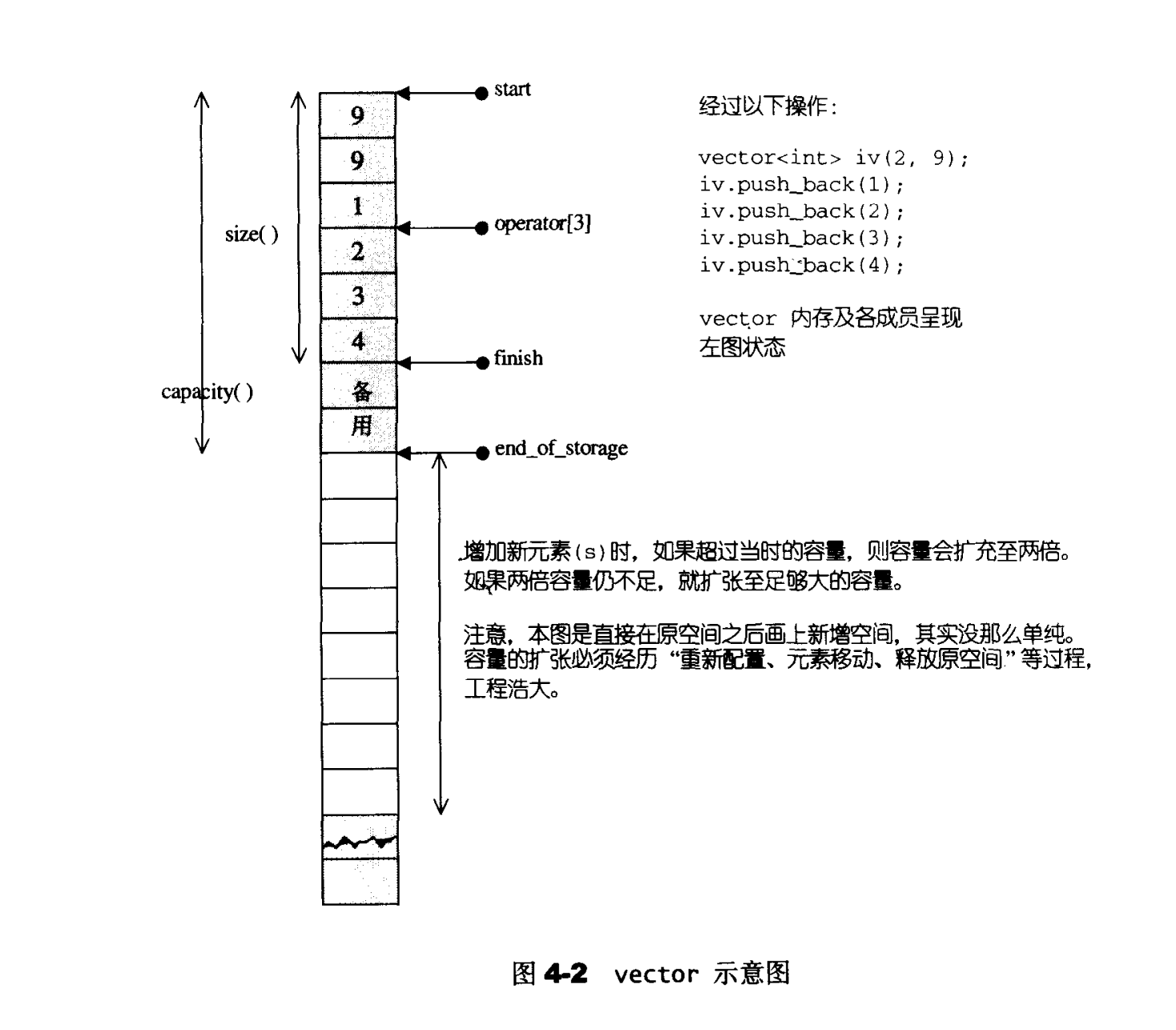
vector的构造与内存管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| template<class T,class Alloc>
void vector<T,Alloc>::insert_aux(iterator position,const T&x){
if(finish!=end_of_strong){
construct(finish,*(finish-1));
++finish;
T x_copy=x;
copy_backward(position,finish-2,finish-1);
*postion=x_copy;
}else{
const size_type old_size=size();
const size_type len=old_size!=0?2*old_size:1;
iterator new_start=data_allocator::allocate(len);
iterator new_finish=new_start;
try{
new_finish=uninitialized_copy(start,position,new_start);
construct(new_finish,x);
++new_finish;
new_finish=uninitialized_copy(position,finish,new_finish);
}
catch(...){
...
}
destory(begin(),end());
deallocate();
start=new_start;
finish=new_finish;
end_of_storage=new_start+len;
}
}
|
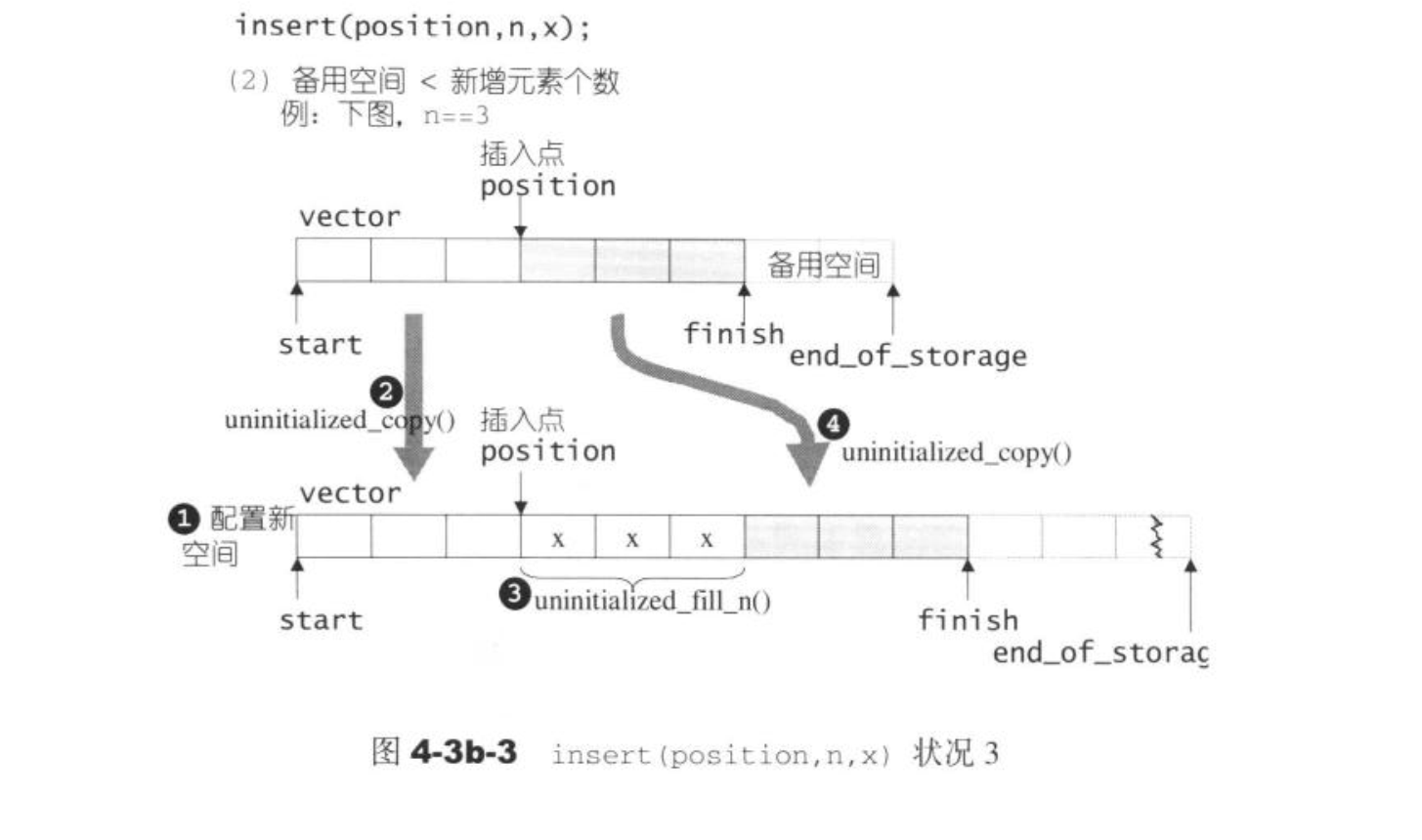
当有备用空间时,示意图如下
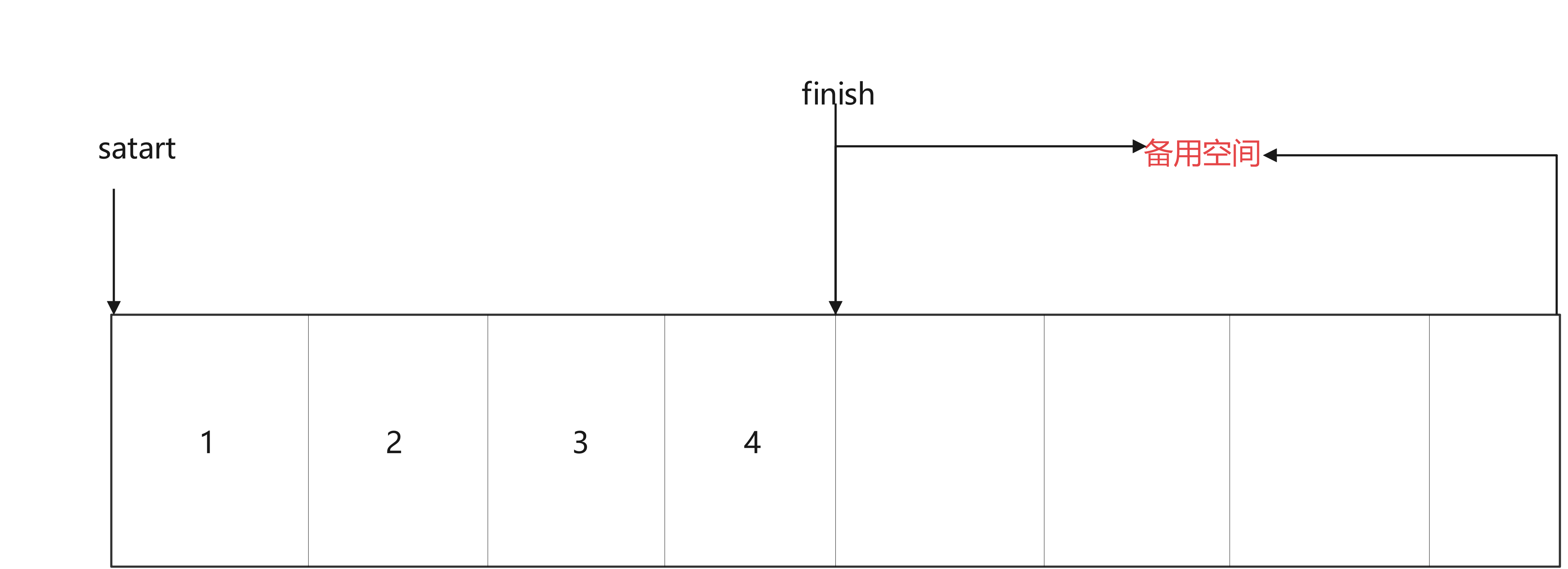
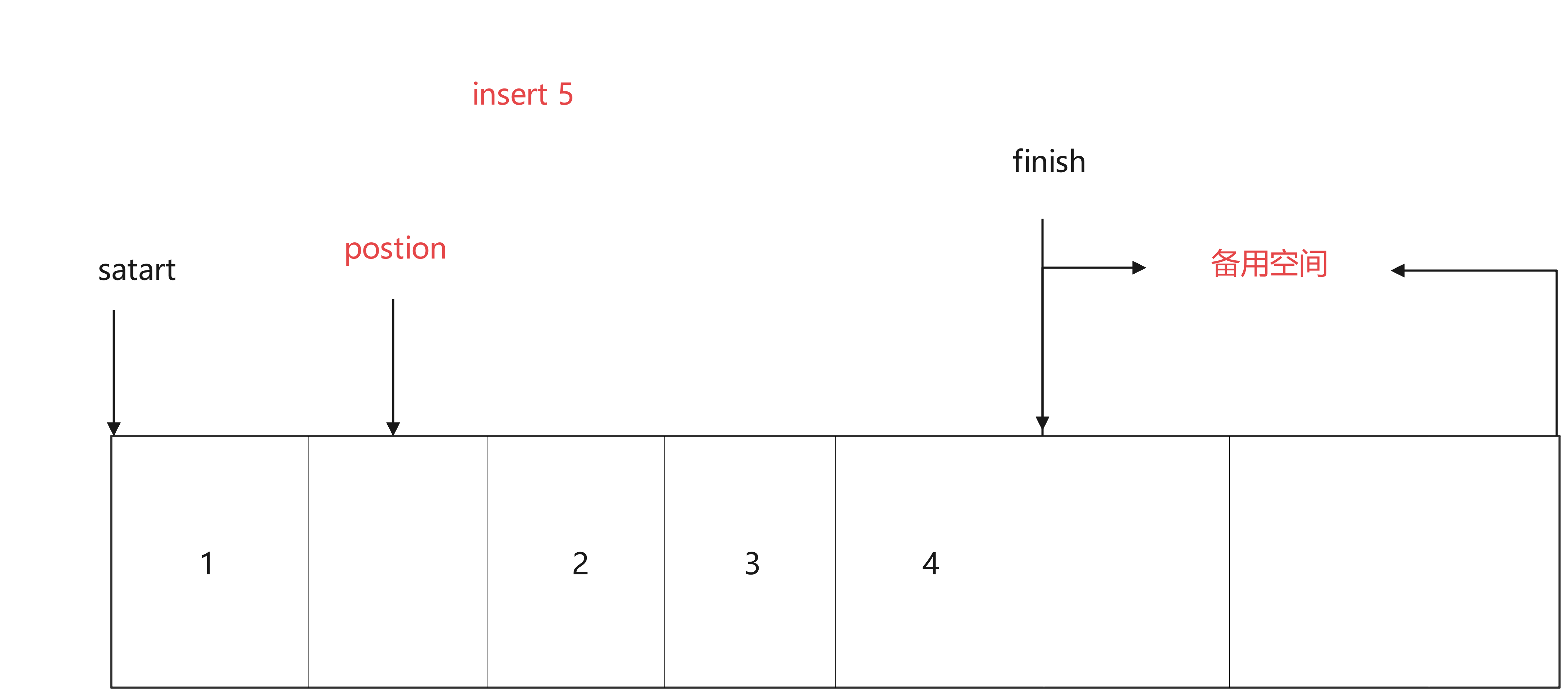
当无备用空间时,先扩展空间,再复制前半段的数据,再插入值,再复制后半段的数据。
vector的元素操作:pop_back,erase,clear,insert
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| //将尾端元素拿掉,并调整大小
void pop_back(){
--finish; //将尾端标记往前移动一格
destory(finish);
}
//清除erase[first,last)中所有元素
iterator erase(iterator first,iterator last){
iterator i=copy(last,finish,first);//把[last,finish]的元素移动到头
destory(i,finish);
finish=finish-(last-first);
return first;
}
//清除某个位置上的元素
iterator erase(iterator position){
if(position+1!=end())
copy(position+1,finish,position);
--finish;
destory(finish);
return position;
}
void clear(){erase(begin(),end());}
|
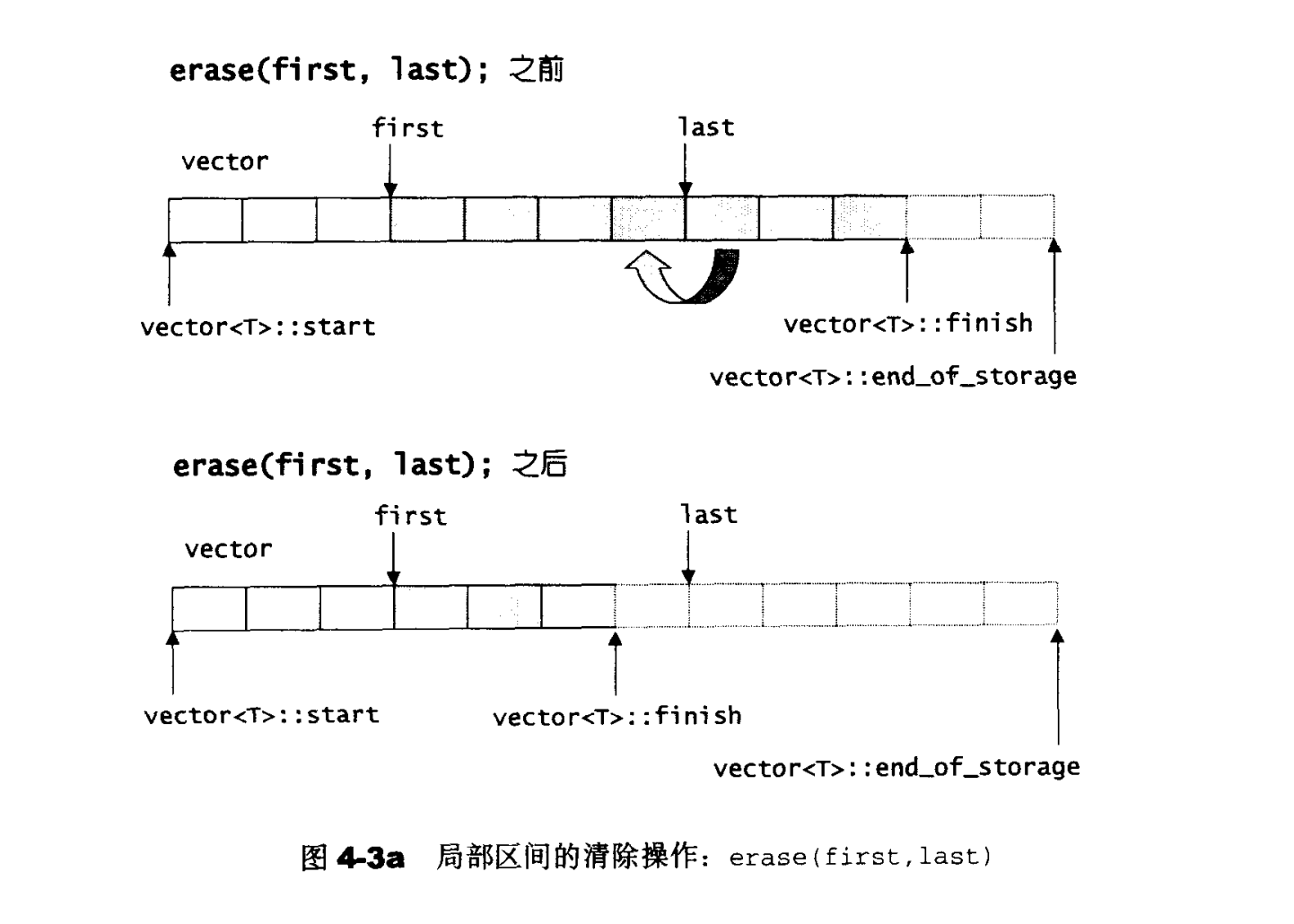
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
template<class T,class Alloc>
void vector<T,Alloc>::insert(iterator position,size_type n,const T&x){
if(n!=0){
if(size_type(end_of_storage-finish)>=n){
T x_copy=x;
const size_type elems_after=finish-position;
iterator old_finish=finish;
if(elems_after>n){
uninitialized_copy(finish-n,finish,finish);
copy_backward(position,old_finish-n,old_finish);
fill(position,position+n,x_copy);
}else{
uninitialize_fill_n(finish,n-elems_after,x_copy);
finish+=n-elems_after;
uninitialize_copy(position,old_finish,finish);
finish+=elems_after;
fill(position,old_finish,x_copy);
}
}else{
const size_type old_size=size();
const size_type len=old_size+max(old_size,n);
iterator new_start=data_allocator::allocate(len);
iterator new_finish=new_start;
new_finish=uinitialized_copy(start,position,new_start);
new_finish=uninitialized_fill_n(new_finish,n,x);
new_finish=uninitialized_copy(position,finish,new_finish);
}
}
}
|
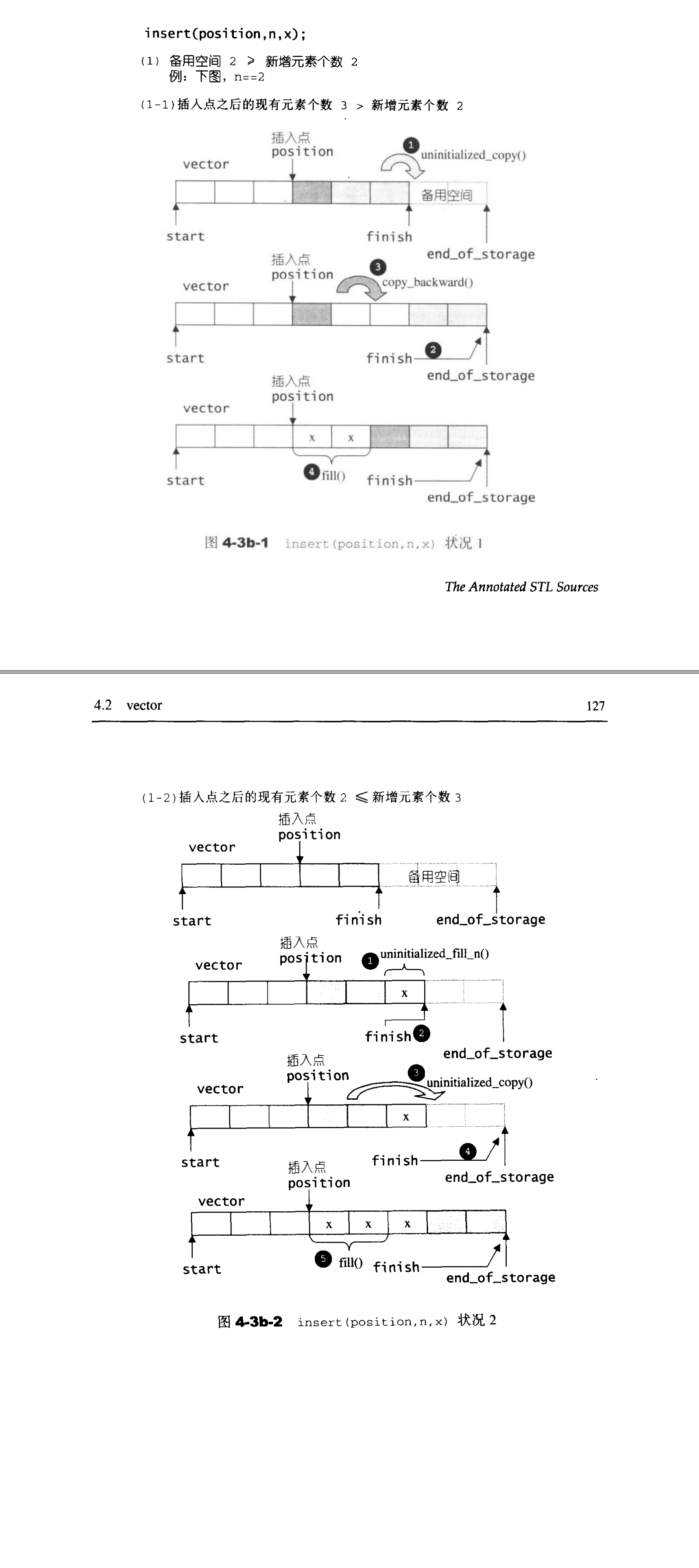
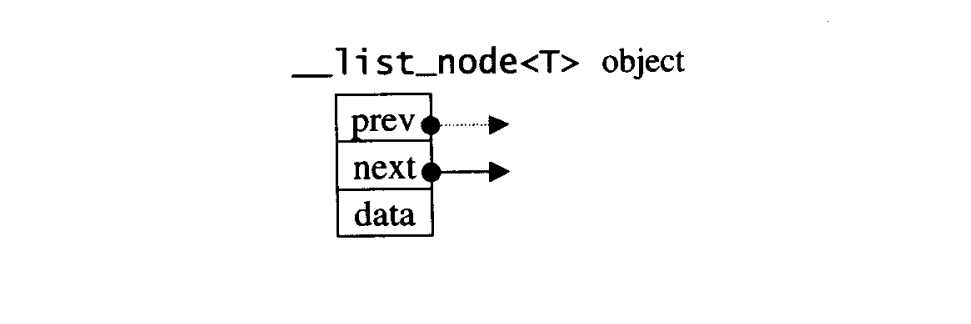
List容器
list节点
1
2
3
4
5
6
7
8
|
template<class T>
struct _list_node{
typedef void*void_pointer;
void_pointer prev;
void_pointer next;
T data;
}
|
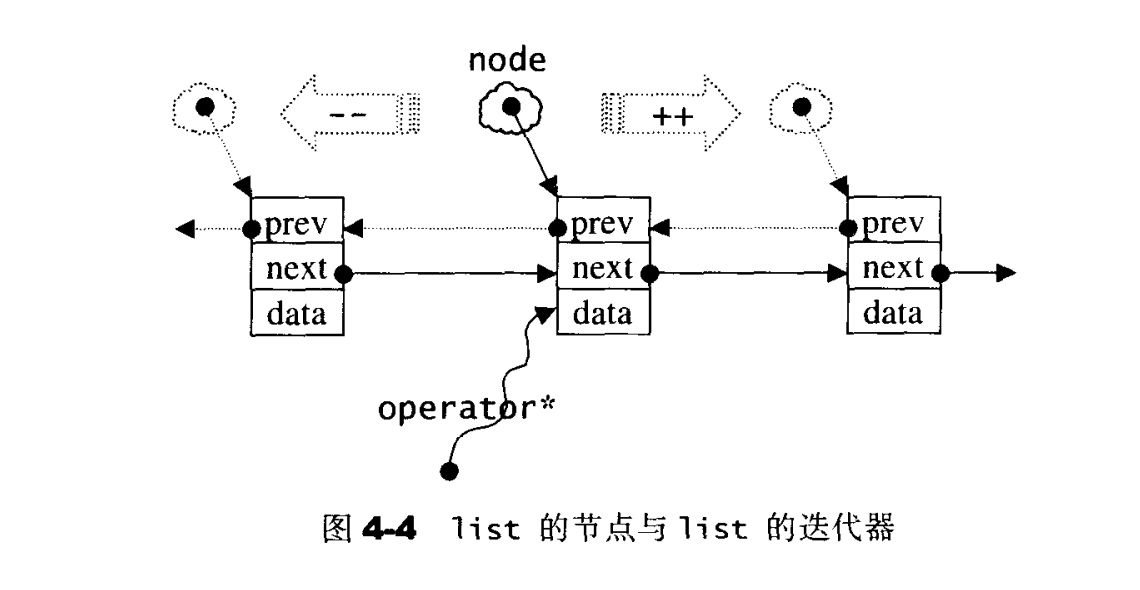
list的迭代器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| template<class T,class Ref,class Ptr>
struct _list_iterator{
typedef _list_iterator<T,T&,T*> iterator;
typedef _list_iterator<T,Ref,Ptr> self;
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef _list_node<T>*link_type;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
link_type node;
self&operator++(){
node=(link_type)(*(node).next);
return *this;
}
self operator++(int){
self temp=*this;
++*this;
return temp;
}
self& operator--(){
node=(link_type)((*node).prev);
return *this;
}
self operator--(){
self temp=*this;
--*this;
return temp;
}
}
|
list的结构是个环状双向链表

list的元素操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
void push_front(const T&x){insert(begin(),x);}
void push_back(const T&x){insert(end(),x);}
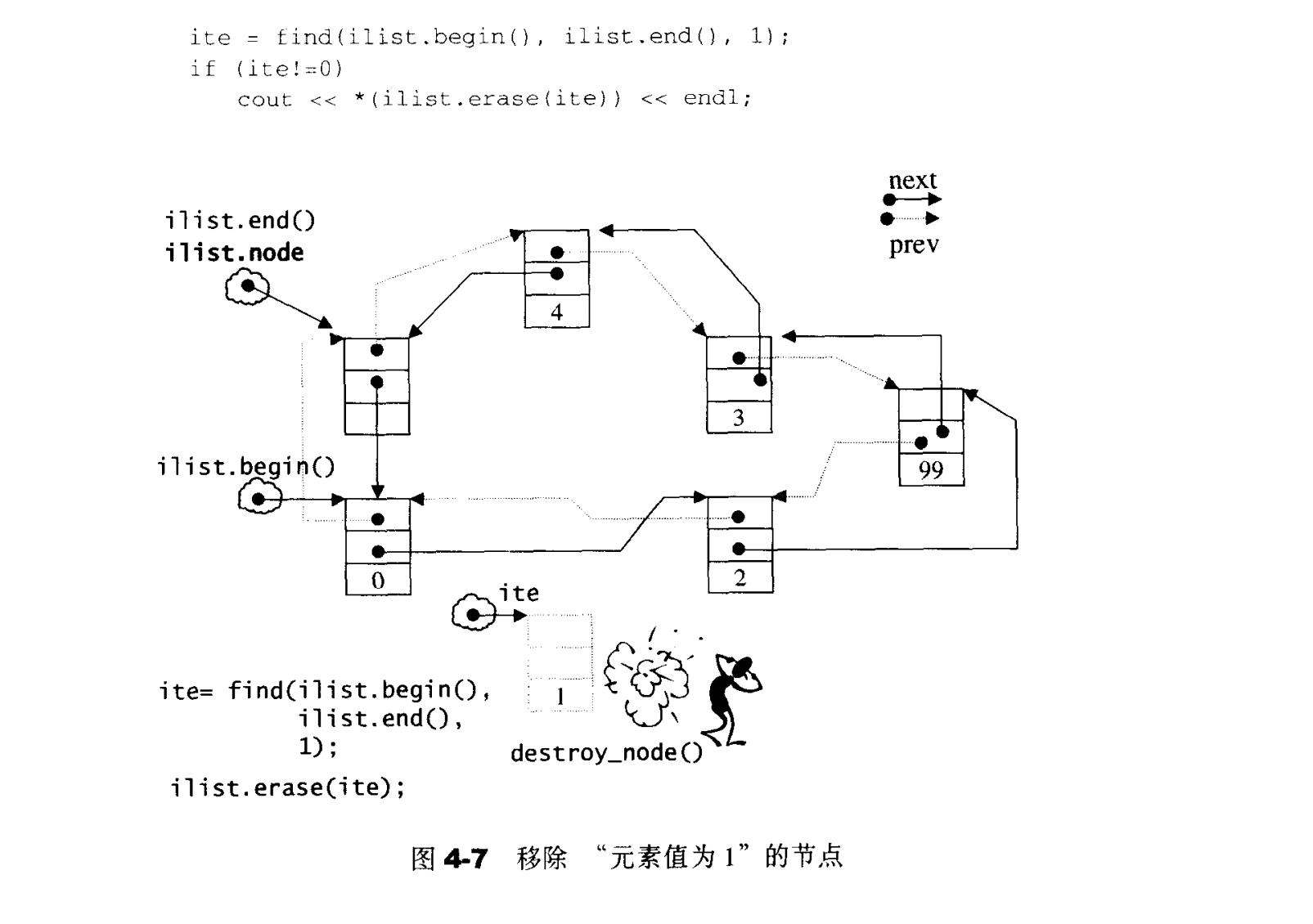
iterator erase(iterator position){
link_type next_node=link_type(position.node->next);
link_type prev_node=link_type(position.node->prev);
prev_node->next=next_node;
next_node->prev=prev_node;
destroy_node(position.node);
return iterator(next_node);
}
void pop_front(){erase(begin());}
void pop_back(){
iterator temp=end();
erase(--temp);
}
template<class T,class Alloc>
void list<T,Alloc>::clear(){
link_type cur=(link_type)node->next;
while(cur!=node){
link_type temp=cur;
cur=(link_type)cur->next;
destroy_node(temp);
}
node->next=node;
node->prev=node;
}
template<class T,class Alloc>
void list<T,Alloc>::remove(const T&value){
iterator first=begin();
iterator last=end();
while(first!=last){
iterator next=first;
++next;
if(*first==value)erase(first);
first=next;
}
}
|
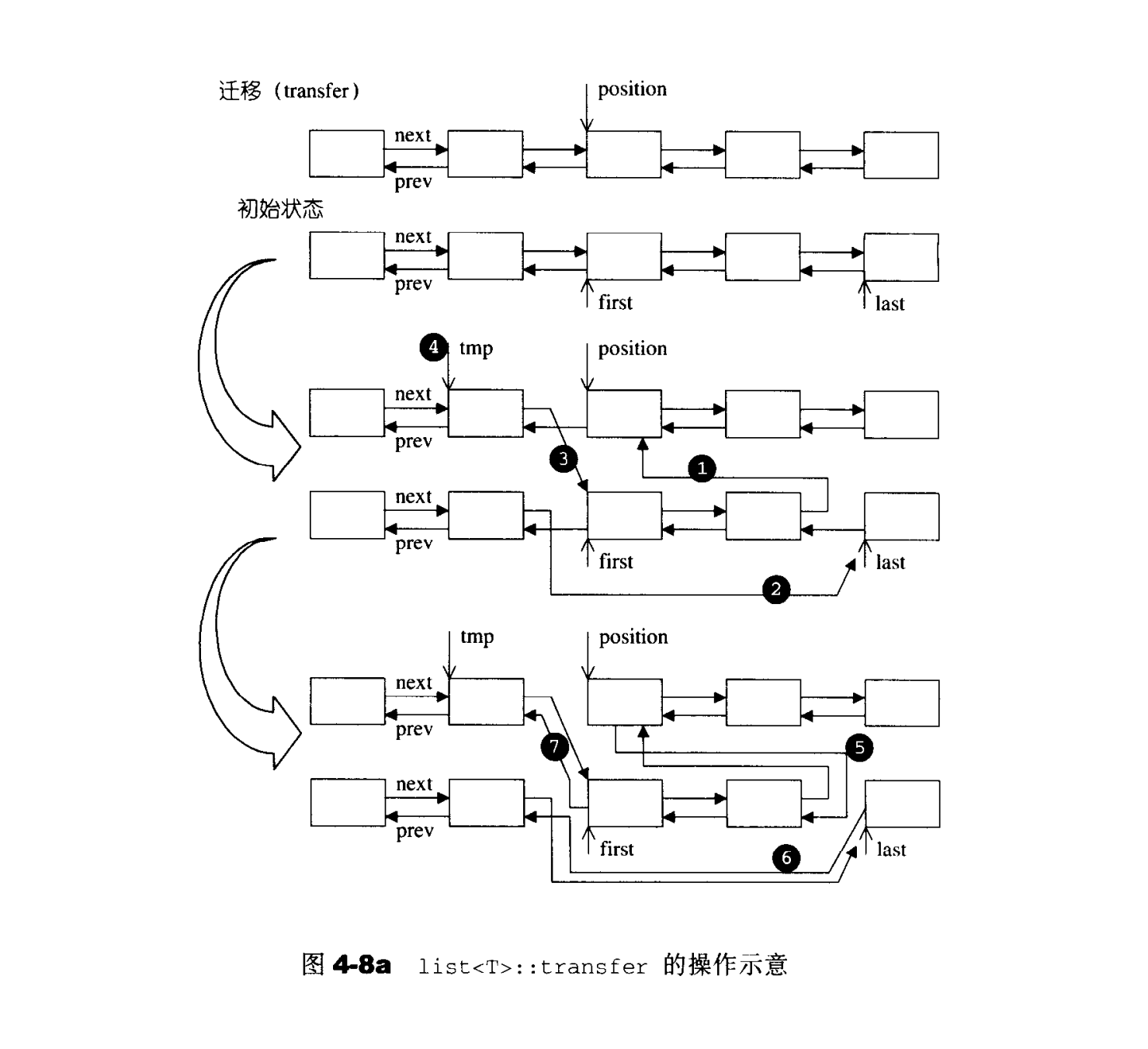
1
2
3
4
5
6
7
8
9
10
11
12
13
| //将[first,last)内所有元素移动到position之前
void transfer(iterator position,iterator first,iterator last){
//过程分为两部,1为先取出[first,last)链表,2再把[first,last)缝合进position
if(position!=last){
(*(link_type)((*last.node).prev))).next=position.node;//使last的上一节点的下一节点指向position
(*(link_type)((*frist.node).prev))).next=last.node;//使frist的上一节点的下一节点指向last,因为不会移动last
(*(link_type)((*position.node).prev))).next=frist.node;//使position节点的上一节点的下一节点指向first
link_type temp=link_type((*position.node).prev);
(*position.node).prev=(*last.node).prev;
(*last.node).prev=(*frist.node).prev;
(*first.node).prev=temp;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
template<class T,class Alloc>
void list<T,Alloc>::merge(list<T,Alloc>&x){
iterator first1=begin();
iterator last1=end();
iterator first2=x.begin();
iterator last2=x.end();
while(first1!=last1 && first2!=last2)
if(*frist2<*frist1){
iterator next=first2;
transfer(first1,first2,++next);
first2=next;
}else
++first1;
if(first2!=last2)transfer(last1,first2,last2);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
template<class T,class Alloc>
void list<T,Alloc>::reverse(){
if(node->next==node||link_type(node->next)->next==node)
return;
iterator first=begin();
++first;
while(first!=end){
iterator old=first;
++first;
transfer(begin(),old,first);
}
}
|
deque容器
deque是一种双向开口的连续线性空间,双向开口指在头尾两端分别做元素的插入和删除操作。
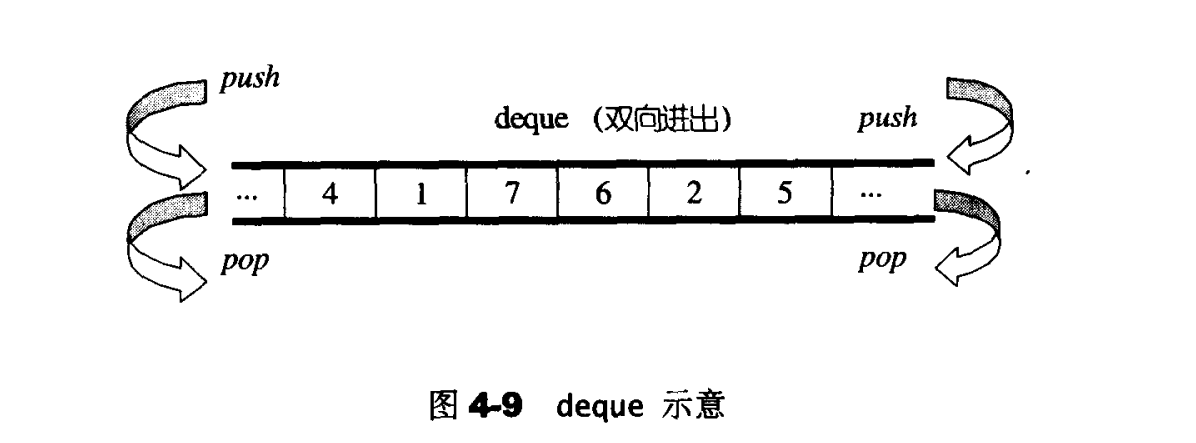
deque与vector的最大差异,一在于deque允许于常数时间内对起头端进行元素的插入或移除操作。二在于deque没有所谓容量观念,因为它是动态地以分段连接空间组合而成,随时可以增加一段新的空间并链接起来。
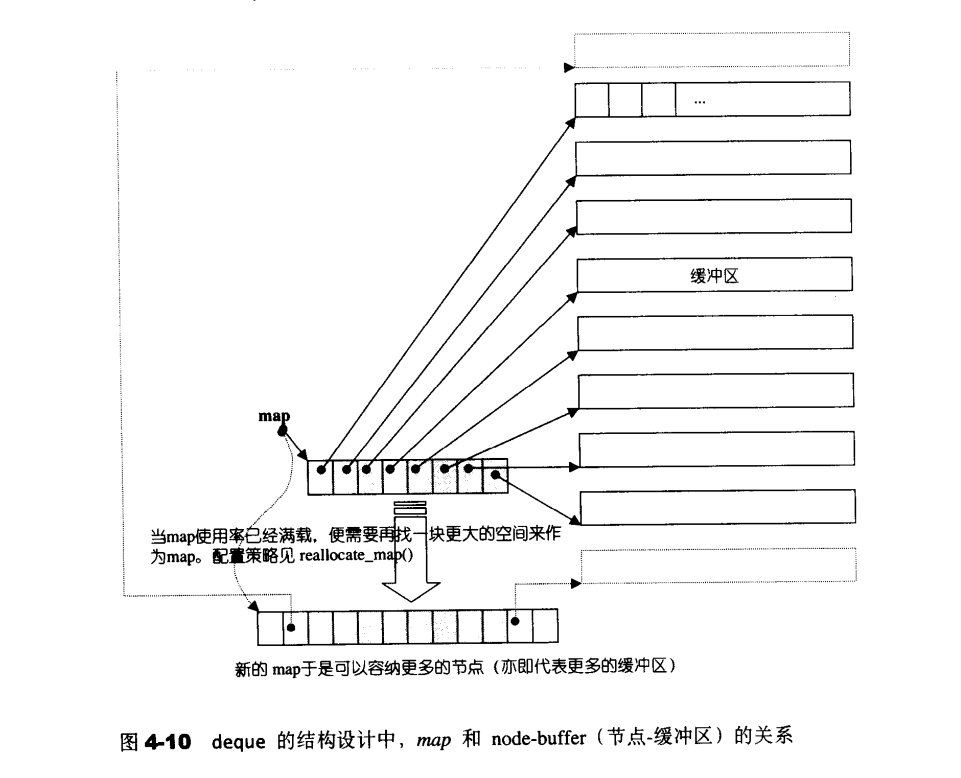
deque的中控器
deque采用一块所为的map作为主控。这里所谓的map是一小块连续空间,其中每个元素都是指针,指向另一段连续线性空间,称为缓冲区,缓冲区才是deque的储存空间主体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| template<class T,class Alloc=alloc,size_t BUfsiz=0>
class deque{
public:
typedef T value_type;
typedef value_type*pointer;
...
protected:
typedef pointer*map_pointer;
protected:
map_pointer map;
size_type map_size;
...
}
|
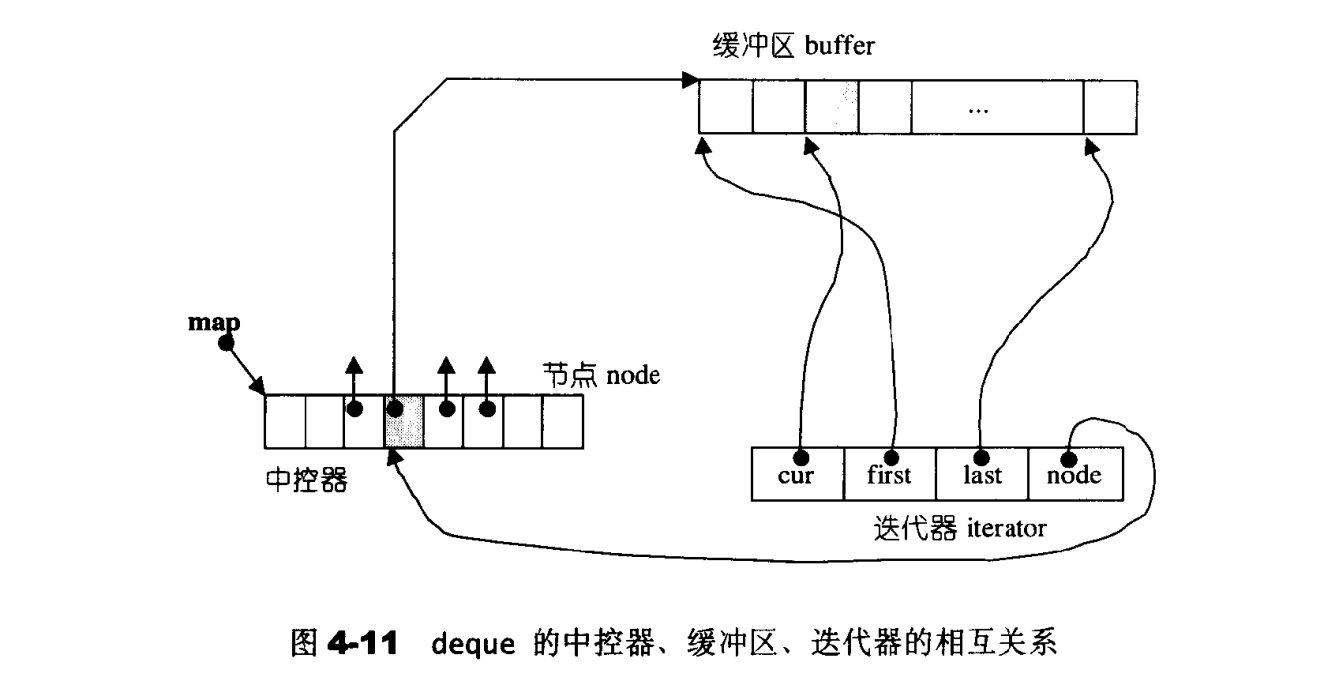
deque的迭代器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| template<class T,class Ref,class Ptr,size_t BufSize>
struct _deque_iterator{
typedef _deque_iterator<T,T&,T*,BufSize> iterator;
typedef _deque_iteartor<T,const T&,const T*,BufSize>const_iterator;
static size_t buffer_size(){return _deque_buf_size(BufSize,sizeof(T));}
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef T**map_pointer;
typedef _deque_iterator self;
T*cur;
T*frist;
T*last;
map_pointer node;
...
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
void set_node(map_pointer new_node){
node=new_node;
first=*new_node;
last=first+difference_type(buffer_size);
}
difference_type operator-(const self&x)const{
return difference_type(buffer_size()*(node-x.node-1)+(cur-first)+(x.last-x.cur));
}
self&operator++(){
++cur;
if(cur==last){
set_node(node+1);
cur=first;
}
return *this;
}
self&operator(){
if(cur==first){
set_node(node-1);
cur=last;
}
--cur;
return *this;
}
slef&operator+=(difference_type n){
difference_type offset=n+(cur-first);
if(offset>0&&offset<difference_type(buffer_size())){
}else{
difference_type node_offset=offset>0?offset/difference_type(buffer_size()):
-difference_type((-offset-1)/buffer_size())-1;
set_node(node+node_offset);
cur=first+(offset-node_offset*difference_type(buffer_size()));
}
return *this;
}
|
deque的数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| template<class T,class Alloc=alloc,size_t BufSize=0>
class deque{
public:
typedef T value_type;
typedef value_type* pointer;
typedef size_t size_type;
public:
typedef _deque_iterator<T,T&,T*,BufSize>iterator;
protected:
typedef pointer* map_pointer;
protected:
iterator start;
iterator finish;
map_pointer map;
size_type map_size;
}
|
1
2
3
4
5
6
7
8
9
10
11
| template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::fill_initialize(size_type n,const value_type&value){
create_map_and_nodes(n);
map_pointer cur;
for(cur=start.node;cur<finish.node;++cur){
uninitialized_fill(*cur,*cur+buffer_size(),value);
}
uninitialize_fill(finish.first,finish.cur,value);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::create_map_and_nodes(size_type num_elements){
size_type num_nodes=num_elements/buffer_size()+1;
map_size=max(initial_map_size(),num_nodes+2);
map=map_allocator::allocate(map_size);
map_pointer nstart=map+(map_size-num_nodes)/2;
map_pointer nfinish=nstart+num_nodes+1;
map_pointer cur;
for(cur=nstart;cur<=nfinish;++cur){
*cur=allocate_node();
}
start.set_node(nstart);
finish.set_node(nfinish);
start.cur=start.first;
finish.cur=finish.first+num_elements%buffer_size();
}
|
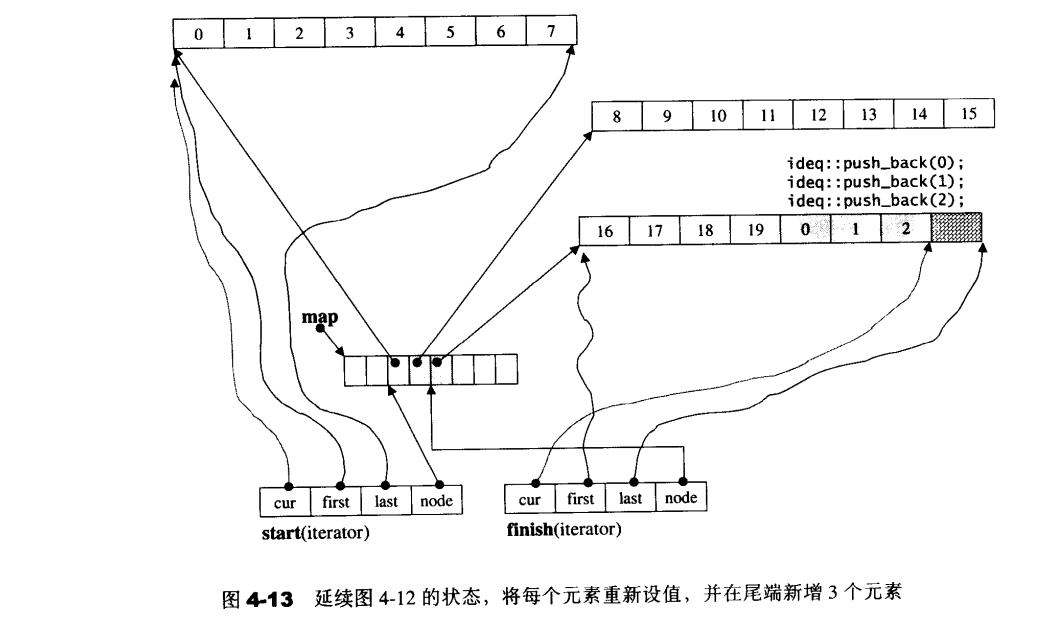
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void push_back(const value_type&t){
if(finish.cur!=finish.last-1){
construct(finish.cur,t);
++finish.cur;
}else{
push_back_aux(t);
}
}
template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,size_t BufSize>::push_back_aux(const value_type&t){
value_type t_copy=t;
reserve_map_at_back();
*(finish.node+1)=allocate_node();
construct(finish.cur,t_copy);
finish.set_node(finish.node+1);
finish.cur=finish.first;
}
|
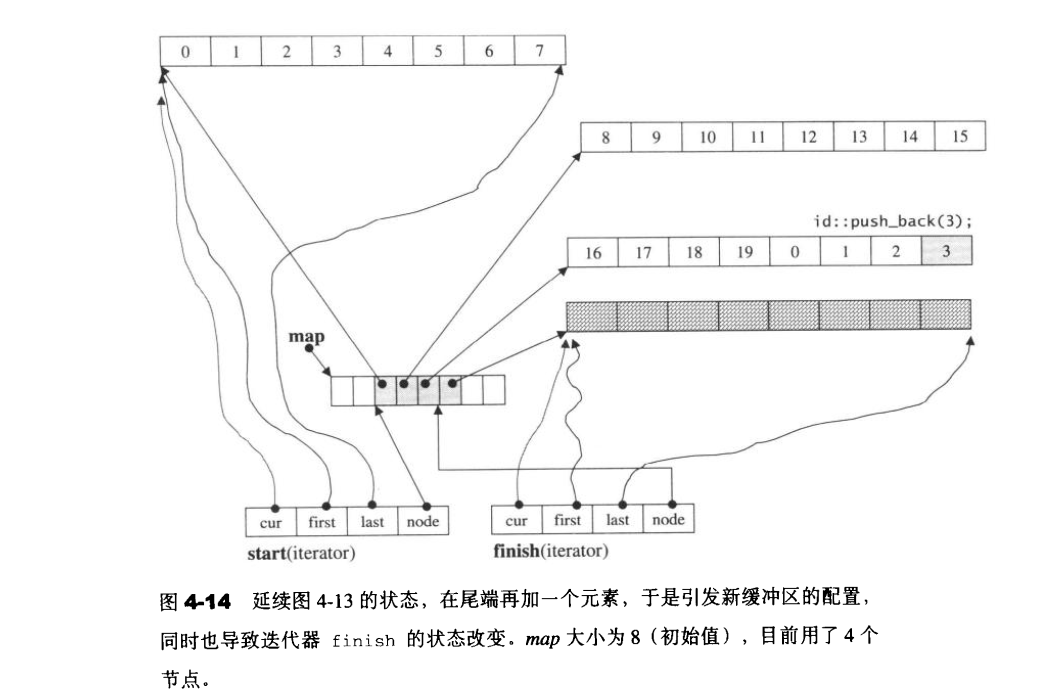
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| void push_front(const value_type&t){
if(start.cur!=start.first){
construct(start.cur-1,t);
--start.cur;
}else{
push_front_aux(t);
}
}
template<class T,class Alloc,size_t BufSize>
void deque<T,class Alloc,size_t BufSize>::push_front_aux(const value_type&t){
value_type t_copy=t;
reserve_map_at_front();
*(start.node-1)=allocate_node();
start.set_node(start.node-1);
start.cur=start.last-1;
construct(start.cur,t_copy);
start.set_node(start.node+1);
start.cur=start.first;
deallcoate_node(*(start.node-1));
}
|
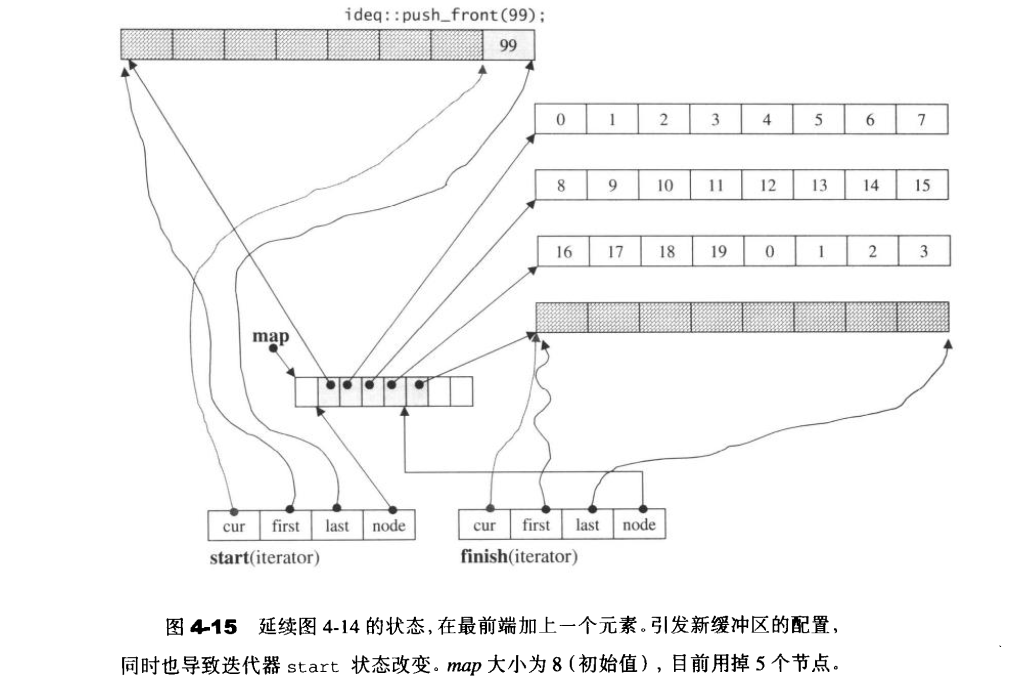
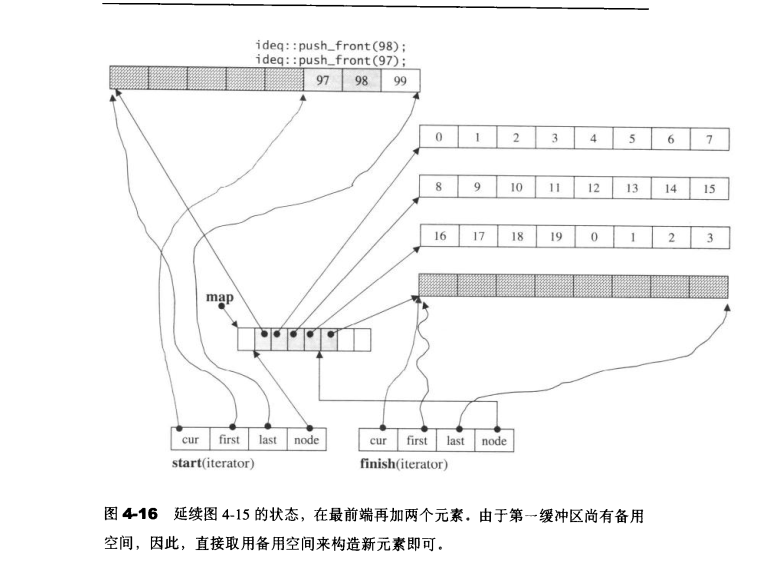
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void push_front(const value_type&t){
if(start.cur!=start.frist){
construct(start.cur-1,t);
--start.cur;
}else
push_front_aux(t);
}
template<class T,class Alloc,size_t BuffSize>
void deque<T,Alloc,BufSize>::push_front_aux(const value_type&t){
value_type t_copy=t;
reserve_map_at_front();
*(start.node-1)=allocate_node();
start.set_node(start.node-1);
start.cur=start.last-1;
construct(start.cur,t_copy);
start.set_node(start_node+1);
start.cur=start.first;
deallocate_node(*(start.node-1));
}
|
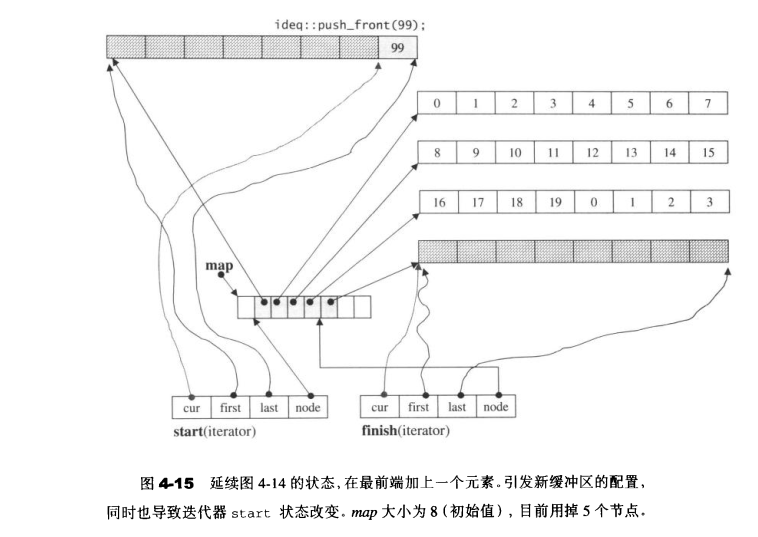
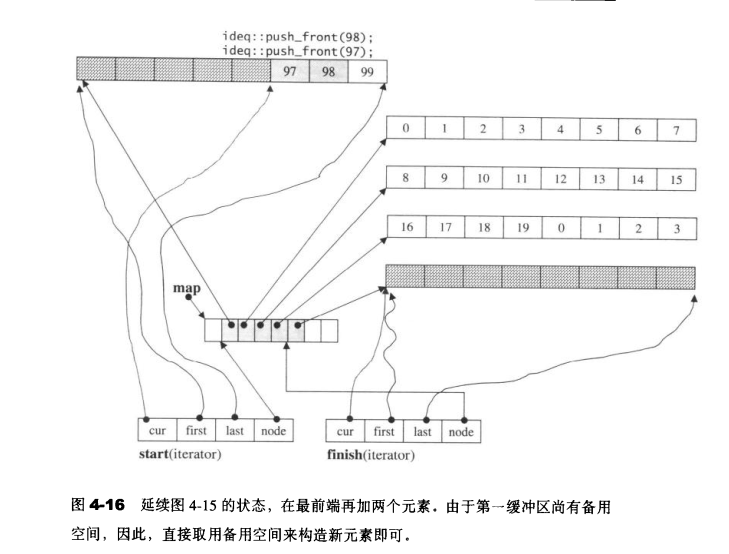
我们判断map什么时候需要重新整治,可以同reserve_map_at_back()和reserve_map_at_front()进行,实际的操作由reallocate_map()进行执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| void reserve_map_at_back(size_type nodes_to_add=1){
if(nodes_to_add+1>map_size-(finish.node-map)){
reallocate_map(nodes_to_add,false);
}
}
void reserve_map_at_front(size_type nodes_to_add=1){
if(nodes_to_add>start.node-map){
reallocate_map(nodes_to_add,true);
}
}
template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BUfSize>::reallocate_map(size_type nodes_to_add,bool add_at_front){
size_type old_num_nodes=finish.node-start.node+1;
size_type new_num_nodes=old_num_nodes+nodes_to_add;
map_pointer new_nstart;
if(map_size>2*new_num_nodes){
new_nstart=map+(map_size-new_num_nodes)/2+(add_at_front?notes_to_add:0);
if(new_nstart<start.node)
copy(start.node,finish.node+1,new_nstart);
else
copy_backward(start.node,finish.node+1,new_nstart+old_num_nodes);
}else{
size_type new_map_size=map_size+max(map_size,nodes_to_add)+2;
map_pointer new_map=map_allocator::allocate(new_map_size);
new_start=new_map+(new_map_size-new_num_nodes)/2+
(add_at_front?nodes_to_add:0);
copy(start.node,finish.node+1,new_nstart);
map_allocator::deallocate(map,map_size);
map=new_map;
map_size=new_map_size;
}
start.set_node(new_nstart);
finish.set_node(new_nstart+old_num_nodes-1);
}
|
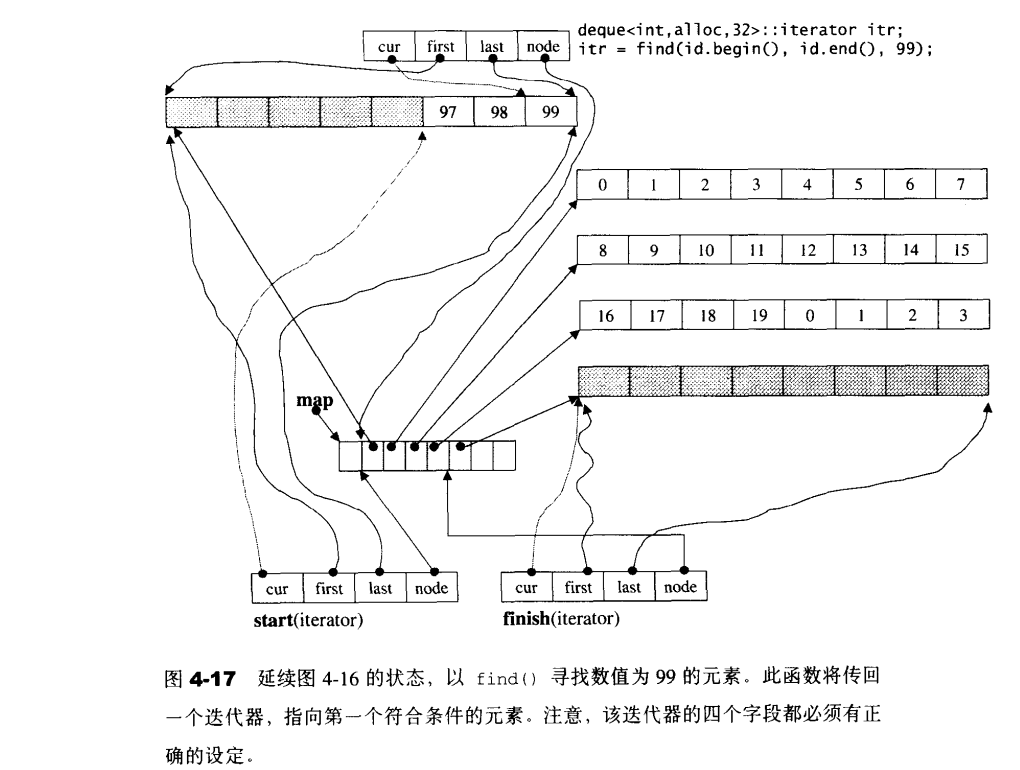
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| void pop_back(){
if(finish.cur!=finish.first){
--frist.cur;
destroy(finish.cur);
}else
pop_back_aux();
}
template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::pop_back_aux(){
deallocate_note(finish.first);
finish.set_node(finish.node-1);
finish.cur=finish.last-1;
destory(finish.cur);
}
void pop_front(){
if(start.cur!=start.last-1){
destory(start.cur);
++start.cur;
}else{
pop_front_aux();
}
}
template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::pop_front_aux(){
destroy(start.cur);
deallocate_node(start.first);
start.set_node(start.node+1);
start.cur=start.first;
}
template<class T,class Alloc,size_t BufSize>
void deque<T,Alloc,BufSize>::clear(){
for(map_pointer node=start.node+1;node<finish.node;++node){
destroy(*node,*node+buffer_size());
data_allocator::deallocate(*node,buffer_size());
}
if(start.node!=finish.node){
destory(start.cur,start.last);
destory(finish.cur,finish.last);
data_allocator::deallocate(finish.first,buffer_size());
}else{
destory(start.cur,finish.cur);
}
finish=start;
}
iterator erase(iterator pos){
iterator next=pos;
++next;
difference_type index=pos-start;
if(index<(size())>>1){
copy_backward(start,pos,next);
pop_front();
}else{
copy(next,finish,pos);
pop_back();
}
return start+index;
}
template<class T,class Alloc,size_t BufSize>
deque<T,Alloc,Bufsize>::iterator
deque<T,Alloc,BufSize>::earase(iterator first,iterator last){
if(first==start&&last==finish){
clear();
return finish;
}else{
difference_type n=last-first;
difference_type elems_before=first-start;
if(elems_before<(size()-n)/2){
copy_backward(start,first,last);
iterator new_start=start+n;
destory(start,new_start);
for(map_pointer cur=start.node;cur<new_start.node;++cur){
data_deallocate::deallocate(*cur,buffer_size());
start=new_start;
}
}else{
copy(last,finish,first);
iterator new_finish=finish-n;
destory(new_finish,fiish);
for(map_pointer cur=new_finish.node+1;cur<=finish.node;++cur){
data_allocator::deallocate(*cur,buffer_size());
}
finish=new_finish;
}
return start+elems_before;
}
}
|
heap(堆)
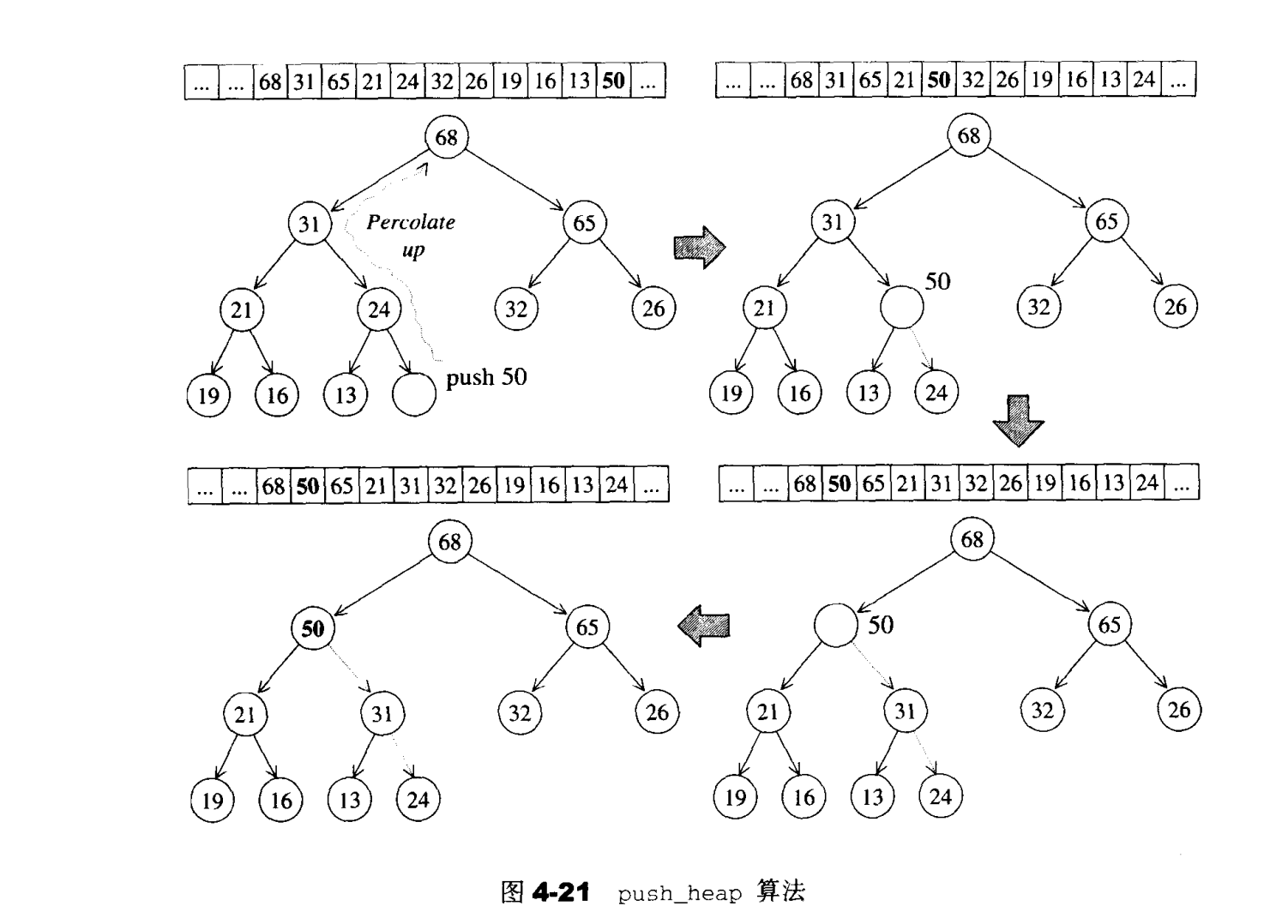
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| template<class RandomAccessIterator>
inline void push_heap(RandomAccessIterator first,RandomAccessIterator last){
_push_heap_aux(fist,last,distance_type(first),value_type(first));
}
template<class RandomAccessIterator,class Distance,class T>
inline void _push_heap_aux(RandomAccessIterator first,RandomAccessIterator last,Distance*,T*){
_push_heap(fist,Distance((last-first)-1),Distance(0),T(*(last-1)));
}
template<class RandomAccessIterator,class Distance,class T>
void _push_heap(RandomAccessIterator first,Distance holeIndex,Distance topIndex,T value){
Distance parent=(holeIndex-1)/2;
while(holeIndex>topIndex&&*(first+parent)<value){
*(first+holeIndex)=*(first+parent);
holeIndex=parent;
parent=(holeIndex-1)/2;
}
*(first+holeIndex)=value;
}
|
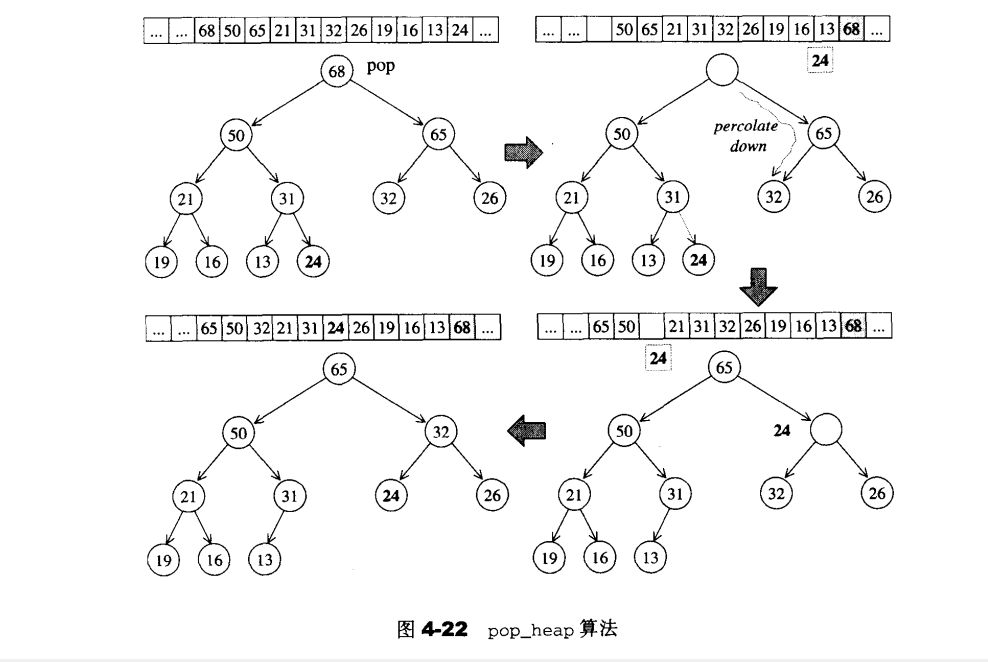
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| template<class RandomAccessIterator>
inline void pop_heap(RandomAccessIteraor first,RandomAccessIterator last){
_pop_heap_aux(first,last,value_type(first));
}
template<class RandomAccessIterator,class T>
inline void _pop_heap_aux(RandomAccessIterator fist,RandomAccessIterator last,T*){
_pop_heap(first,last-1,last-1,T(*(last-1)),distance_type(first));
}
template<Class RandomAccessIteartor,class T,class Distance>
inline void _pop_heap(RandomAccessIterator first,RadomAccessIterator last,
RandomAccessIterator result,T value,Distance*){
*result=*frist;
_adjust_heap(fist,Distance(0),Distance(last-first),value);
}
template<class RandomAccessIterator,class Distance,class T>
void _adjust_heap(RandomAccessIteartor first,Distance holeIndex,Distance len,T value){
Distance topIndex=holeIndex;
Distance secondChild=2*holeIndex+2;
while(secondChild<len){
if(*(first+secondChild)<*(first+(secondChild-1)))
secondChild--;
*(first+holeIndex)=*(first+secondChild);
holeIndex=secondChild;
secondChild=2*(secondChild+1);
}
if(secondChild==len){
*(first+holeIndex)=*(first+(secondChild-1));
holeIndex=secondIndex-1;
}
}
template<class RandomAccessIterator>
void sort_heap(RandomAccessIterator first,RandomAccessIterator last){
while(last-first>1){
pop_heap(first,last--);
}
}
|
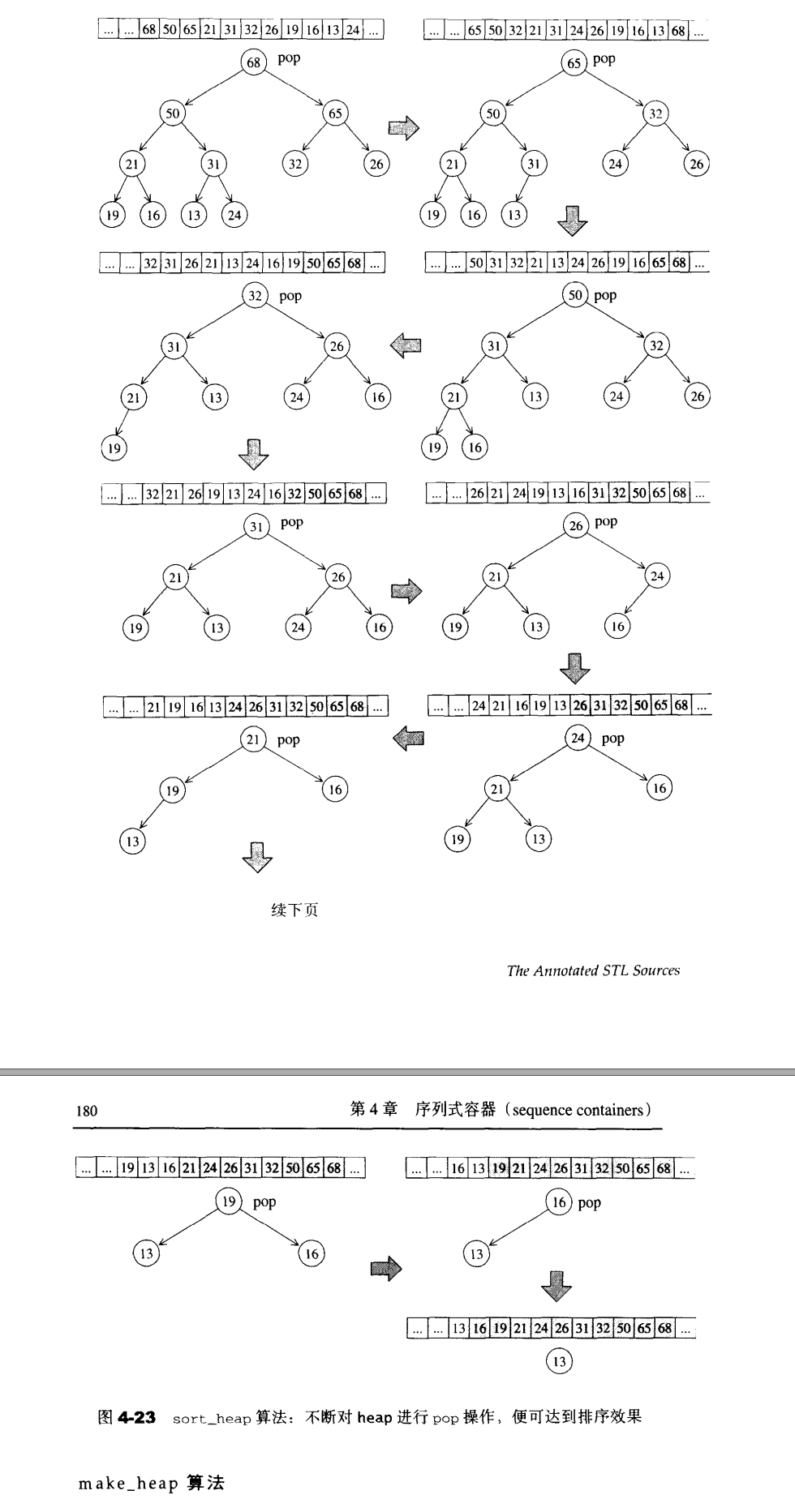
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| template<class RandomAccessIterator>
inline void make_heap(RandomAccessIterator frist,RandomAccessIterator last){
_make_heap(first,last,value_type(first),distance_type(first));
}
template<class RandomAccessIterator,class T,class Distance>
void _make_heap(RandomAccessIterator first,RandomAccessIterator last,T*,Distance*){
if(last-first<2)return;
Distance parent=(len-2)/2;
while(true){
_adjust_heap(first,parent,len,T(*(first+parent)));
if(parent==0)return;
parent--;
}
}
|
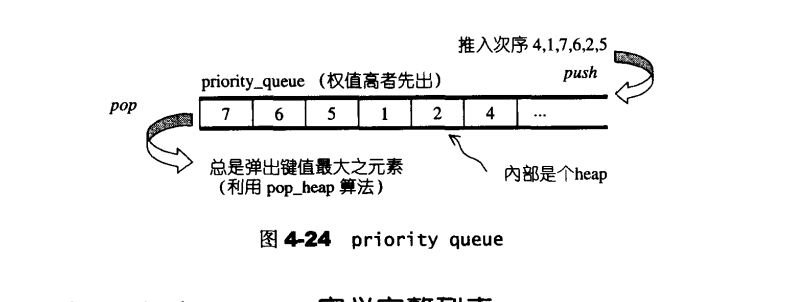
priority_queue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| template<class T,class Sequence=vector<T>,
class Compare=less<typename Sequence::value_type>>
class priority_queue{
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c;
Compare comp;
public:
priority_queue():c(){}
explicit priority_queue(const Compare&x):c(),comp(x){}
template<class InputIterator>
priority_queue(InputIterator first,InputIterator last,const Compare&x)
:c(first,last){
make_heap(c.begin(),c.end(),comp);
}
priority_queue(InputIterator first,InputIterator last)
:c(first,last){
make_heap(c.begin(),c.end(),comp);
}
bool empty()const{
return c.empty();
}
size_type size()const{
return c.size();
}
const_reference top()const{
return c.front();
}
void push(const value_type&x){
c.push_back(x);
push_heap(c.begin(),c.end(),comp);
}
void pop(){
pop_heap(c.begin(),c.end(),comp);
c.pop_back();
}
}
|
slist
slist为单向链表。
slit的节点
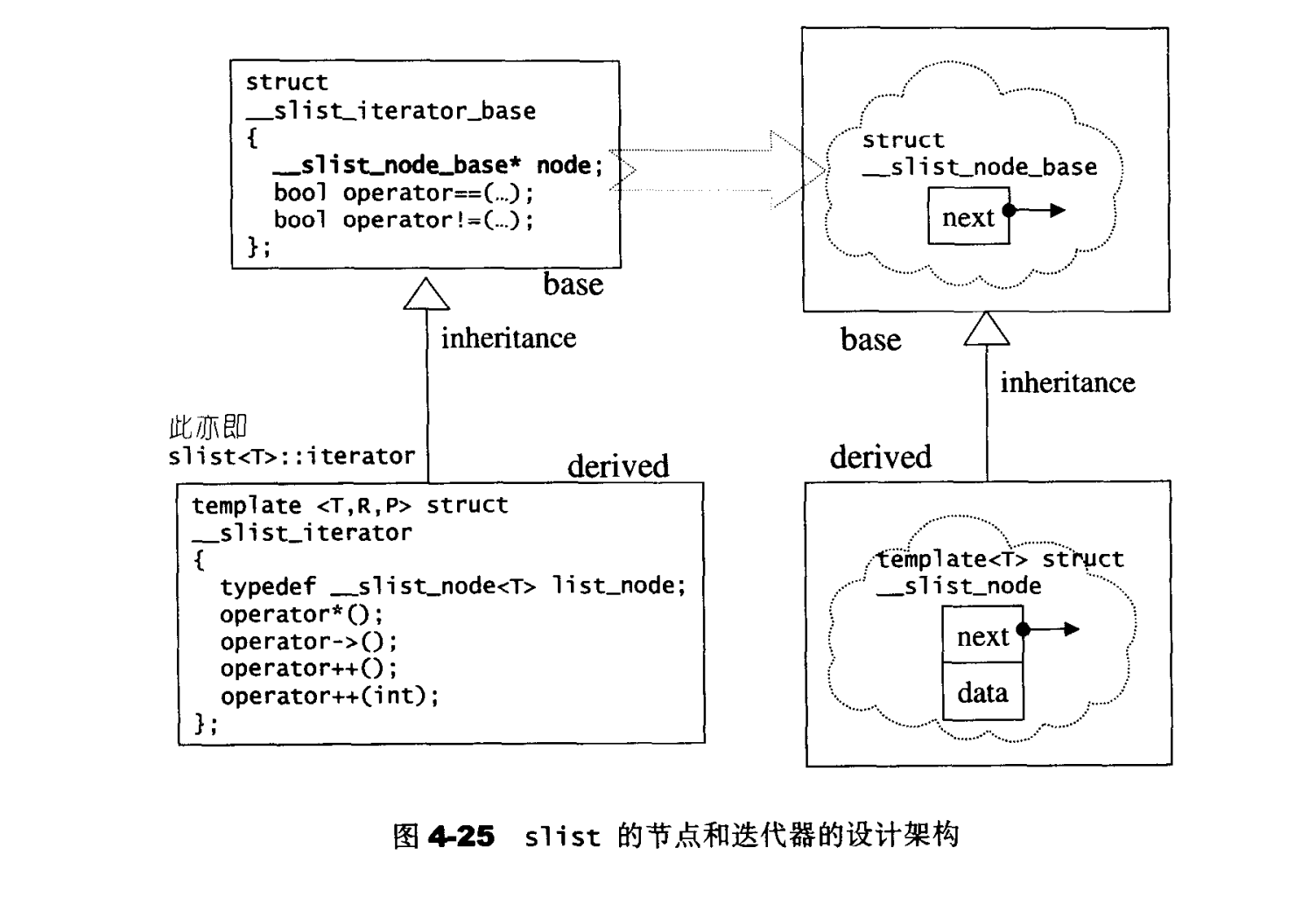
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
struct _slist_node_base{
_slist_node_base*next;
}
template<class T>
struct _slist_node:public _slist_node_base{
T data;
}
inline _slist_node_base*_slist_make_link(_slist_node_base*prev_node,_slist_node_base*new_node){
new_node->next=prev_node->next;
prev_node->next=new_node;
return new_node;
}
inline size_t _slist_size(_slist_node_base*node){
size_t result=0;
for(;node!=0;node=node->next)
++result;
return result;
}
|
slist迭代器
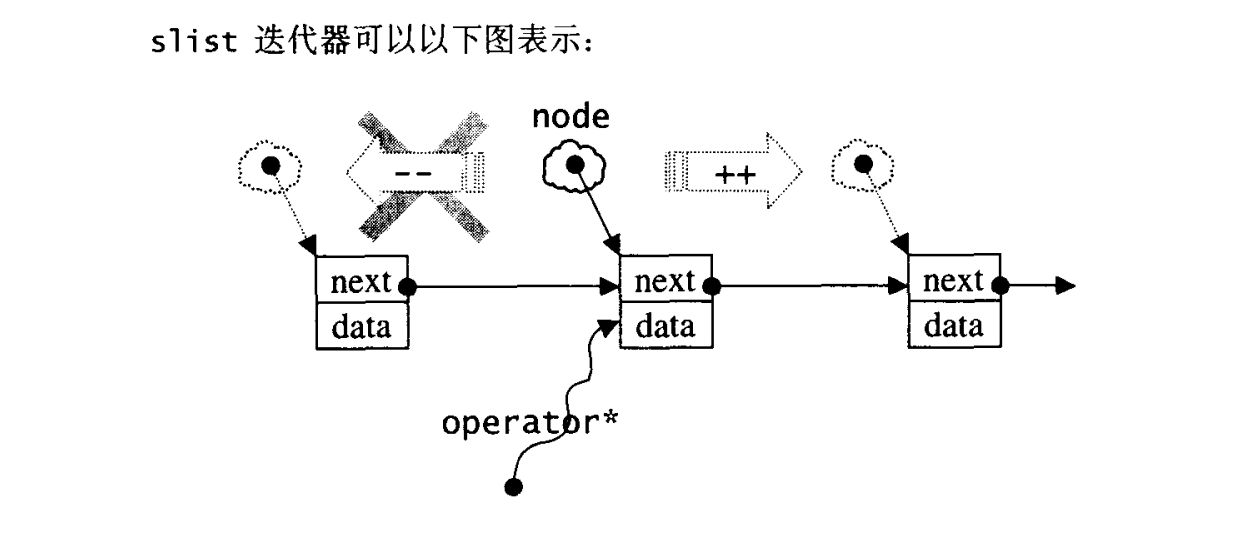
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
struct _slist_iterator_base{
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef forward_iterator_tag iterator_category;
_slist_node_base*node;
_slist_iterator_base(_slist_node_base*x):node(x){}
void incr(){
node=node->next;
}
void operator==(const _slist_iterator_base&x)const{
return node==x.node;
}
void operator!=(const _slist_iterator_base&x)const{
return node!=x.node;
}
};
template<class T,class Ref,class Ptr>
struct _slist_iterator:public _slist_iterator_base{
typedef _slist_iterator<T,T&,T*> iterator;
typedef _slist_iterator<T,const T&,const T*>const_iterator;
typedef _slist_iterator<T,Ref,Ptr>self;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
tyepdef _slist_node<T> list_node;
_slist_iterator(list_node*x):_list_iterator_base(x){}
_slist_iterator():_slist_iterator_base(0){}
_slist_iterator(const iterator:x):_slist_iterator_base(x.node){}
reference operator*()const{
return ((list_node*)node)->data;
}
pointer operator->()const{
return &(operator*());
}
self&operator++(){
incr();
return *this;
}
self operator++(int){
self temp=*this;
incr();
return temp;
}
}
|
slist的数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| template<class T,class Alloc=alloc>
class slist{
public:
typedef T value_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type& reference;
typedef const value_type& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef _slist_iterator<T,T&,T*> interator;
typedef _slist_iterator<T,const T&,const T*>const_iterator;
private:
typedef _slist_node<T> list_node;
typedef _slist_node_base list_node_base;
typedef _slist_iterator_base iterator_base;
typedef simple_alloc<list_node,Alloc>list_node_allocator;
static list_node*create_node(const value_type&x){
list_node*node=list_node_allocator::allocate();
construct(&node->data,x);
node->next=0;
return node;
}
static void destroy_node(list_node*node){
destory(&node->data);
list_node_allocator::deallocate(node);
}
private:
list_node_base head;
public:
slist(){head.next=0;}
~slist(){clear();}
public:
iterator begin(){
return iterator((list_node*)head.next);
}
iterator end(){
return iterator(0);
}
size_type size()const{
return _slist_size(head.size);
}
bool empty()const{
return head.next=0;
}
void swap(slist&L){
list_node_base*temp=head.next;
head.next=L.head.next;
L.head.next=temp;
}
public:
reference front(){
return ((list_node*)head.next)->data;
}
void push_front(const value_type&x){
_slist_make_link(&head,create_node(x));
}
void pop_front(){
list_node*node=(list_node*)head.next;
head.next=node->next;
destroy_node(node);
}
}
|
关联式容器
平衡二叉树
普通二叉树与平衡二叉树的区别是,当一些随机输入值插入树中时,普通二叉树会出现极度不平衡的情况,该情况会导致插入、查找 、删除相较于平衡二叉树有较差的效率。而平衡二叉树可以自动调整,使得整个树保持在一个平衡的状态。
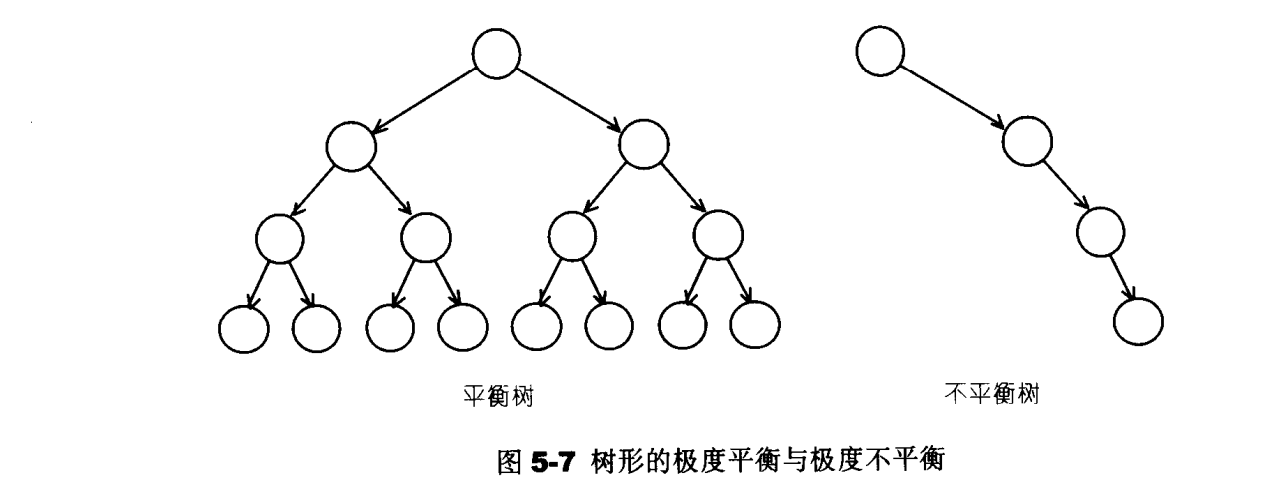
AVL tree
AVL tree是一个”加上额外平衡条件”的二查搜索树。其平衡条件的建立是为了确保整棵树的深度为O(logN)。
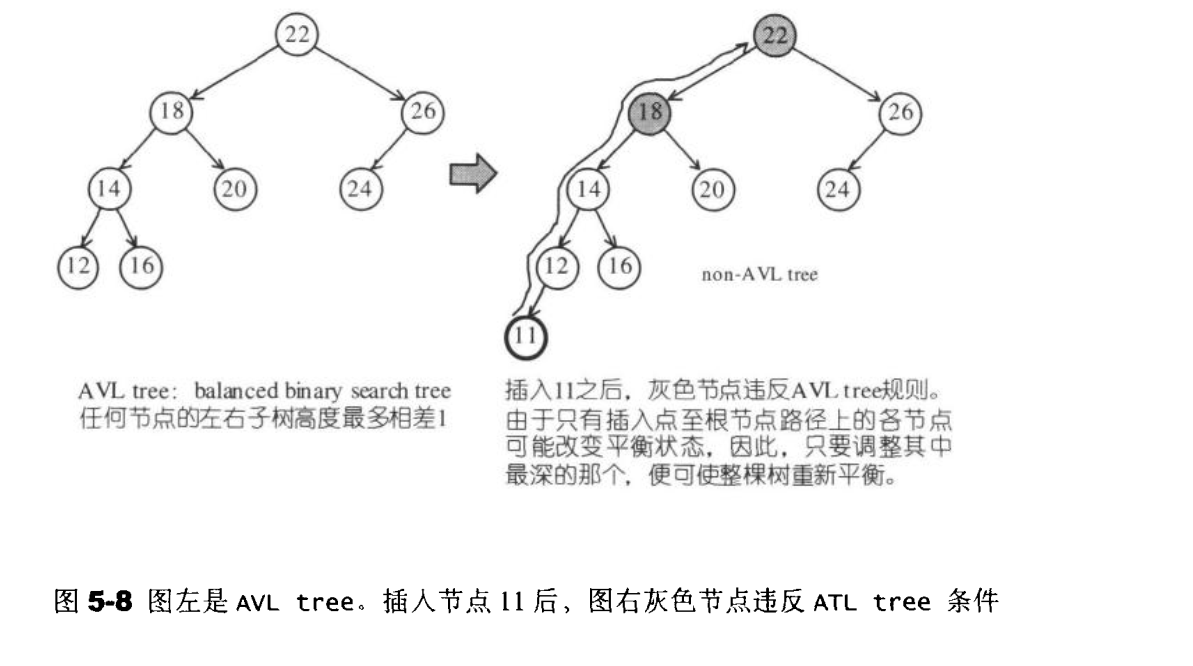
在插入了节点11之后,灰色节点违反了AVL tree 的平衡条件.只有插入点至根节点路径上的各节点有可能改变平衡状态。因此,只需要调整其中最深的那个节点,便可使得整棵树重新获得平衡。
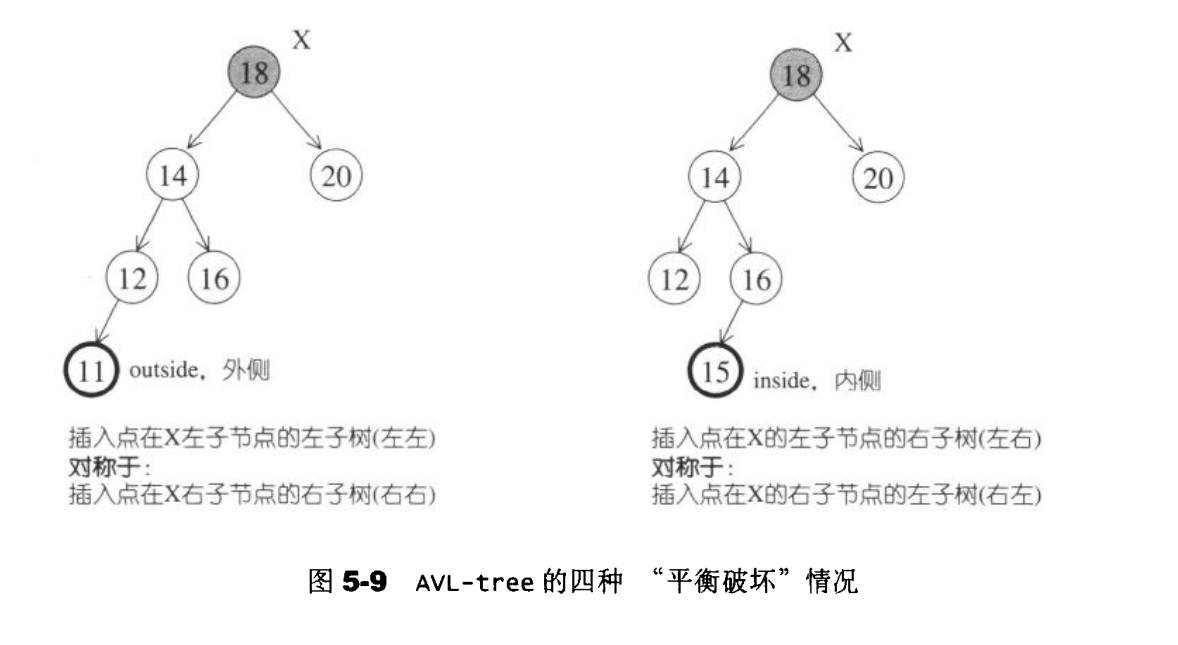
假设最深节点为X,由于节点最多拥有有两个子节点,而所谓”平衡被破坏”意味着X的左右两棵子树的高度为相相差为2,因此我们可以将情况分为以下四种情况。
- 插入点位于X的左子节点的左子树——左左
- 插入点位于X的左子节点的右子树——左右
- 插入点位于X的右子节点的左子树——右左
- 插入点位于X的右子节点的右子树——右右
情况1,4彼此对称 ,称为外侧插入。采用单侧旋转来调整。而情况2,3彼此对称 ,称为内侧插入,采用双旋转操作来调整。
单旋转
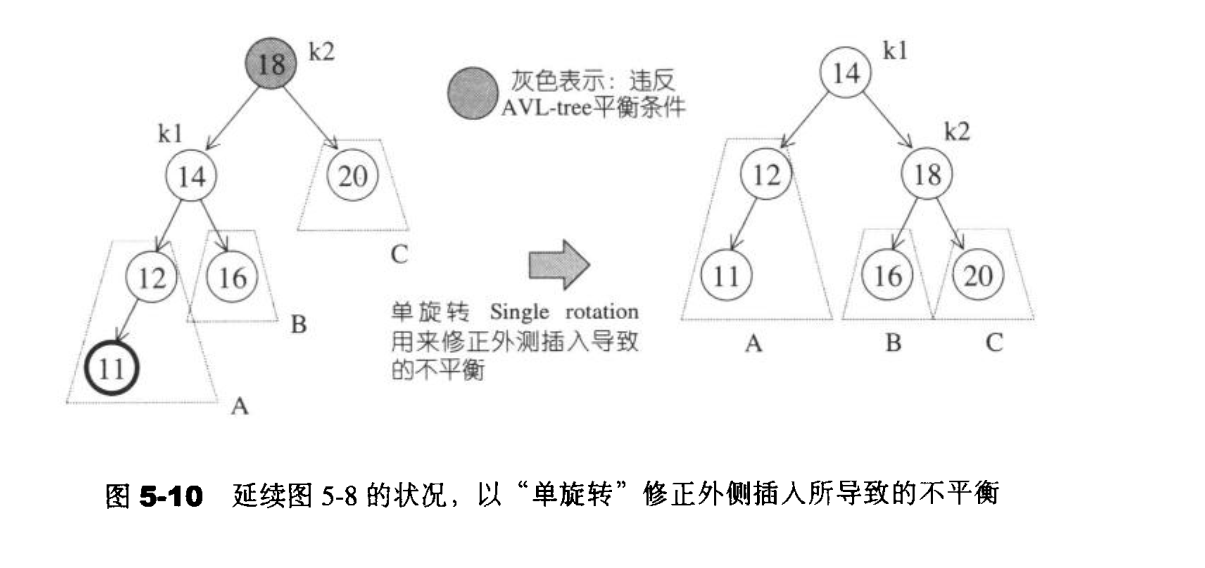
我们把键值11插入后,导致左右两边深度不平衡。在18的左边深度为3,而右边的深度为1。故我们需要对该树进行旋转操作。
双旋转
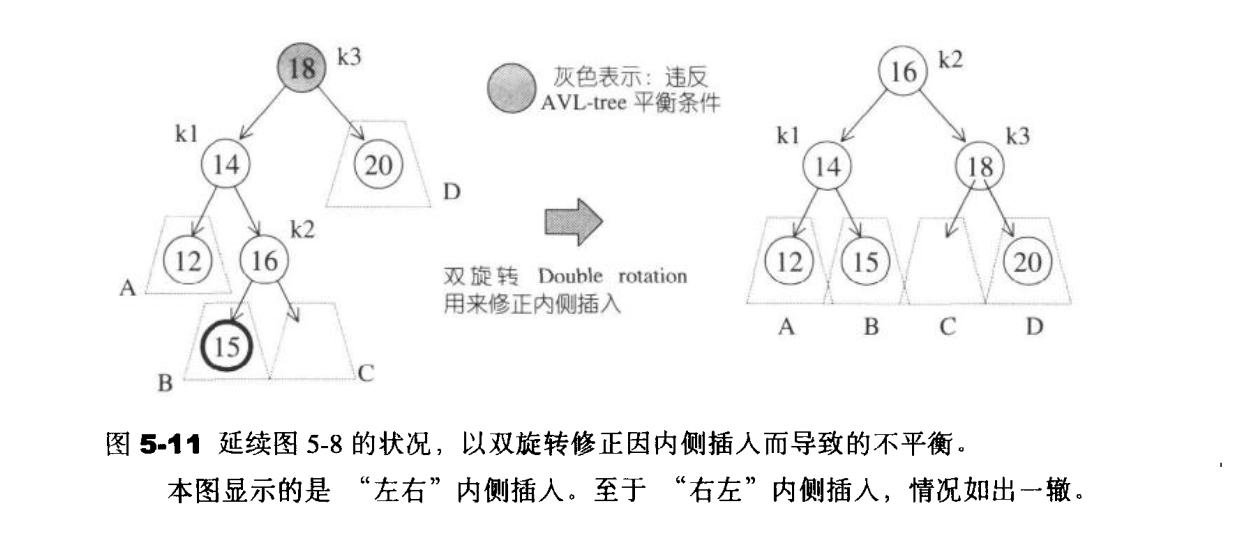
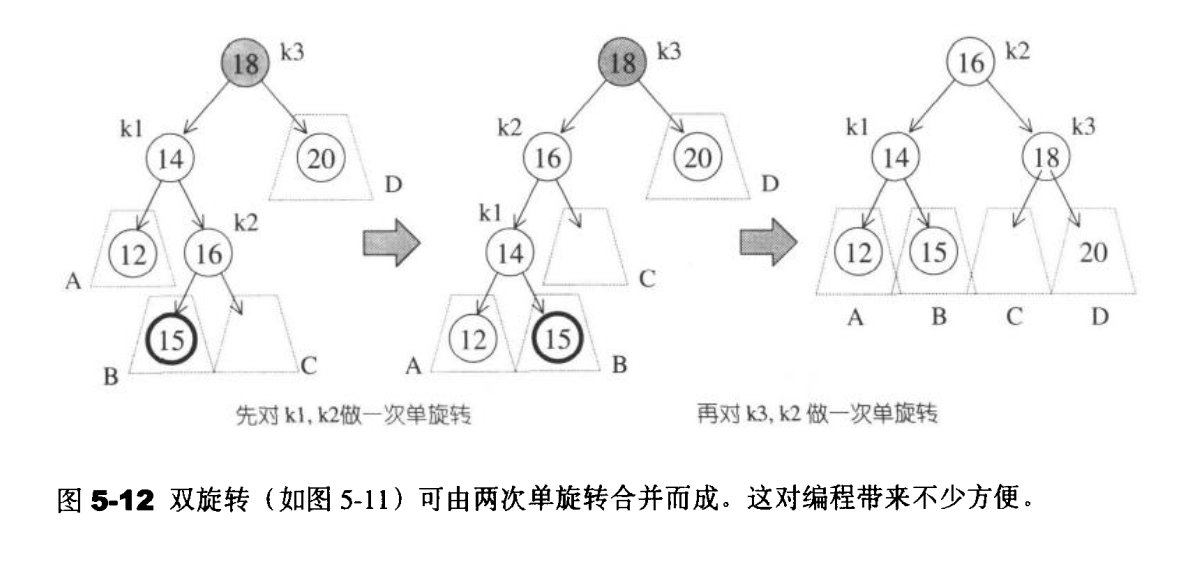
双旋转主要是修正因内侧插入而导致的不平衡。
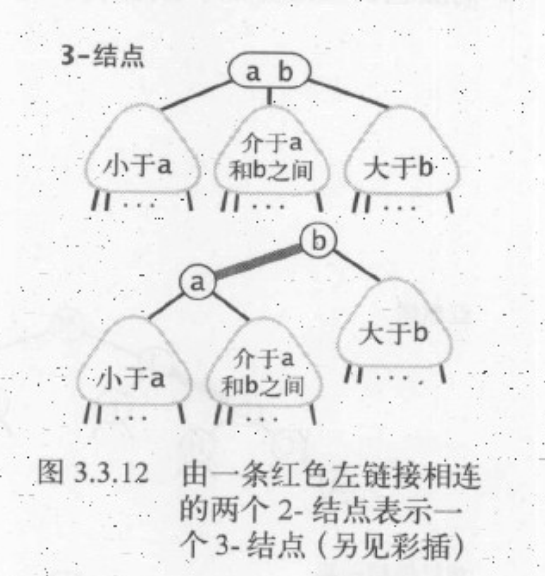
2-3查找树
为了保证查找树的平衡性,我们需要允许在树中的一个结点保存多个键。
定义:一棵2-3查找树或为一棵空树,由以下结点组成。 2-结点,含有一个键(及其对应的值)和两条链接,左链接指向的2-3树中的键都小于该结点,右链接指向的2-3树中的键都大于该结点。3-结点,含有两个键(及其对应的值)和三条链接,左链接指向的2-3树中的键都小于该结点,中链接指向的2-3树中的键都位于该结点的两个键之间。右链接指向的2-3树中的键都大于该结点。
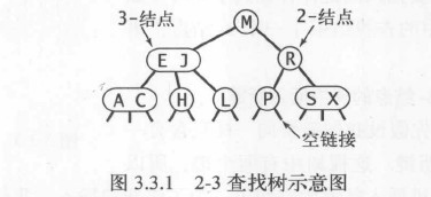
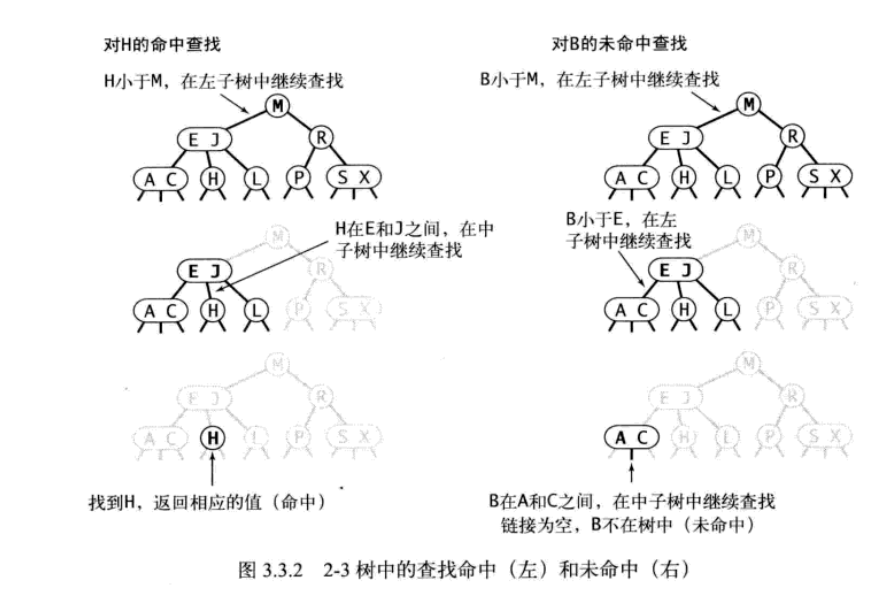
一棵完美平衡的2-3查找树中的所有空链接到根结点的距离应该都相同。
将二叉查找树的查找算法一般化我们能直接得到2-3树的查找算法。要判断一个键是否存在树中。我们先将它和根结点中的键比较。如果它和其中任意一个相等,查找命中。否则,我们根据比较的结果找到指向相应区间的链接,并在其指向的子树中递归地继续查找。如果这是个空链接,查找未命中。
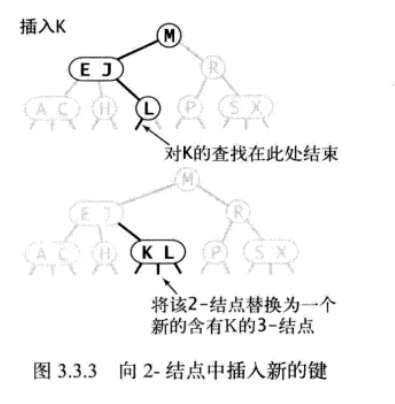
向2-结点中插入新键
向一棵只含有一个3-结点的树中插入新键
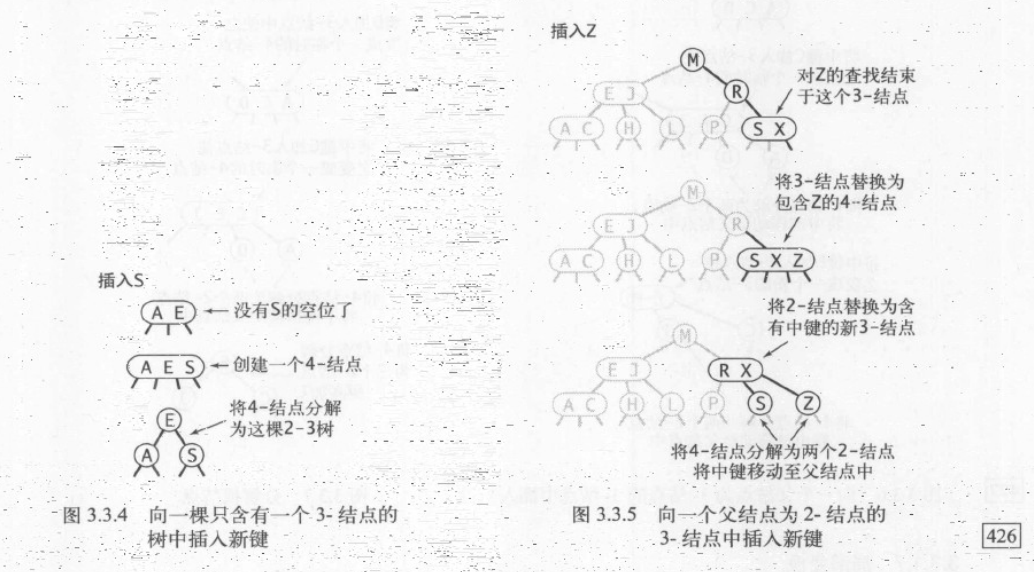

2-3树的变化过程
2-3树的构造过程
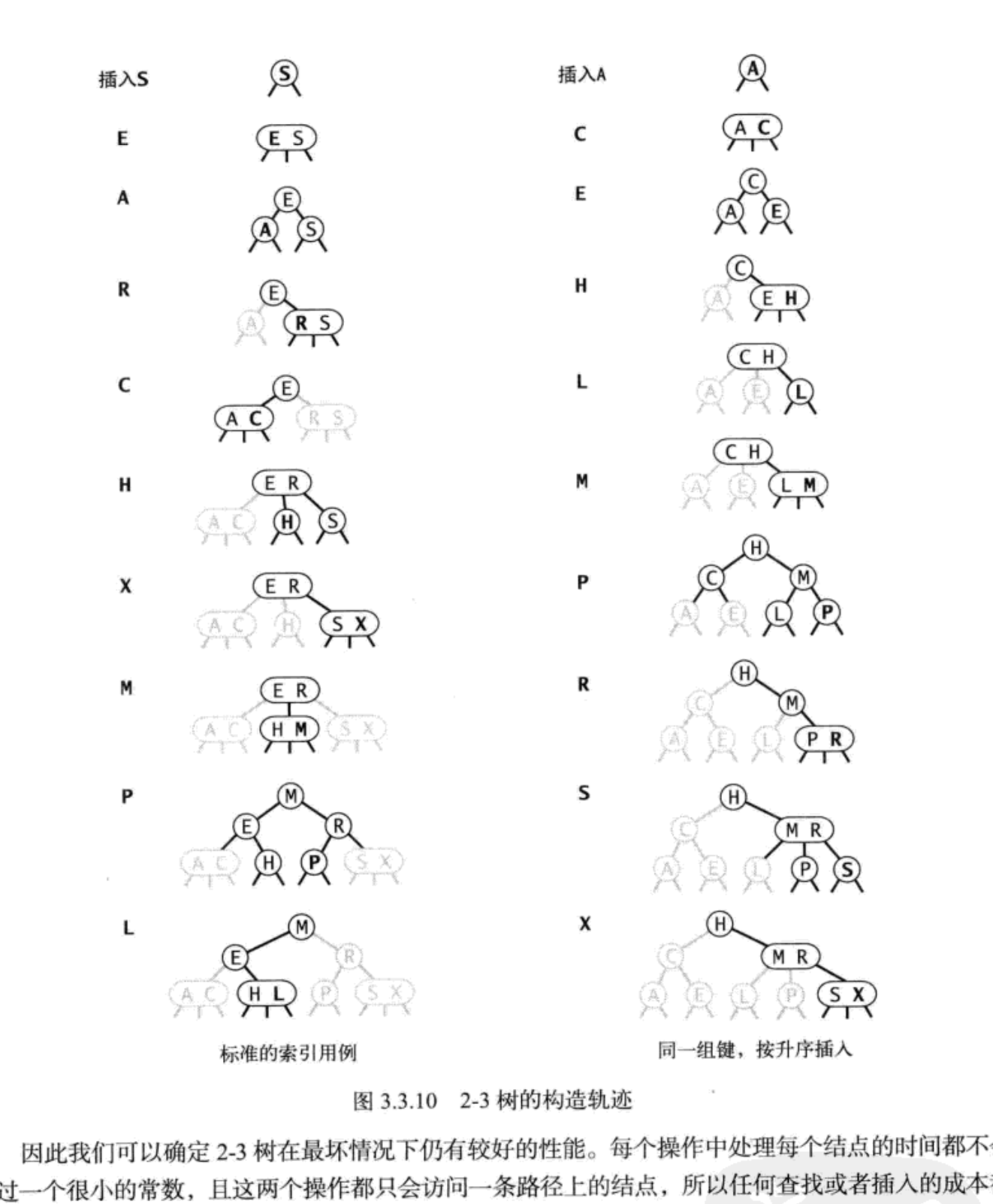
2-3查找树的删除过程
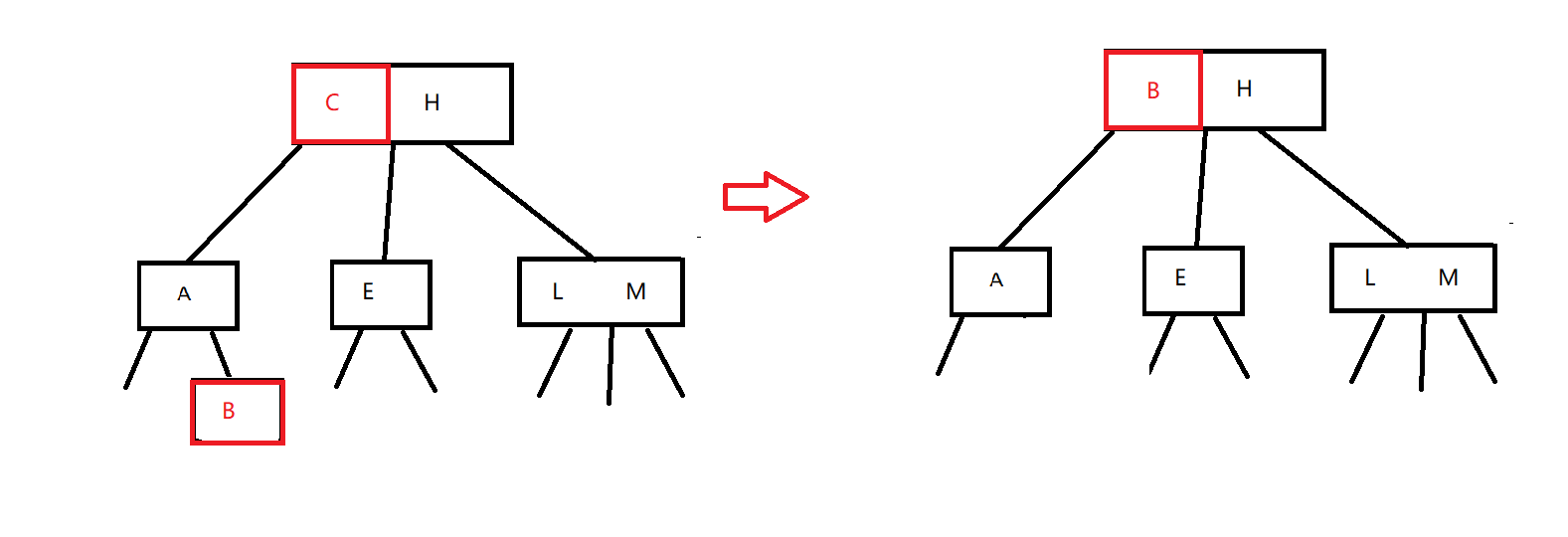
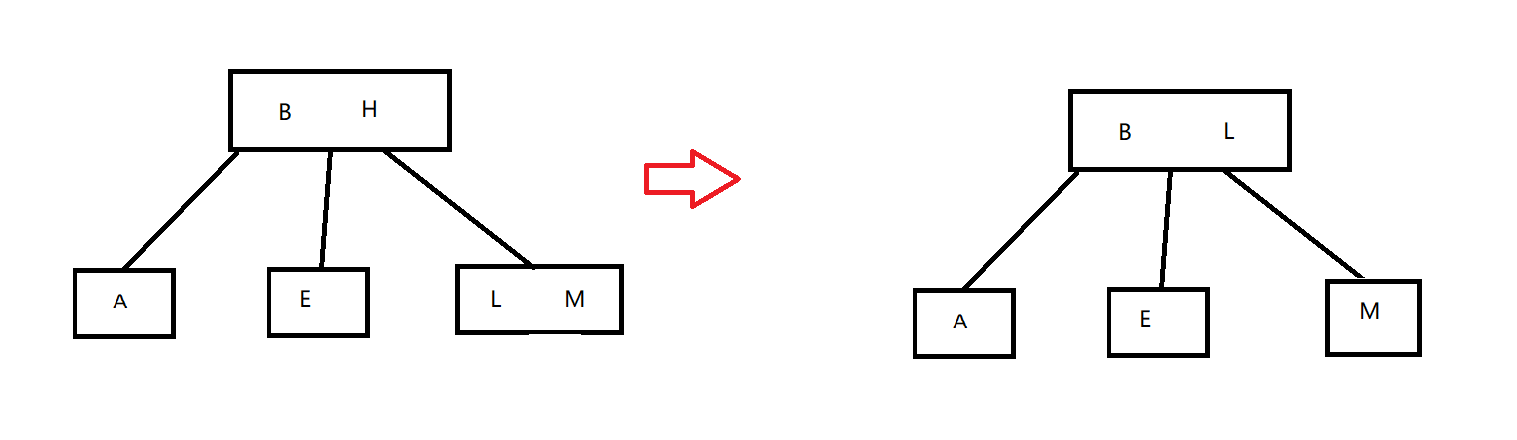
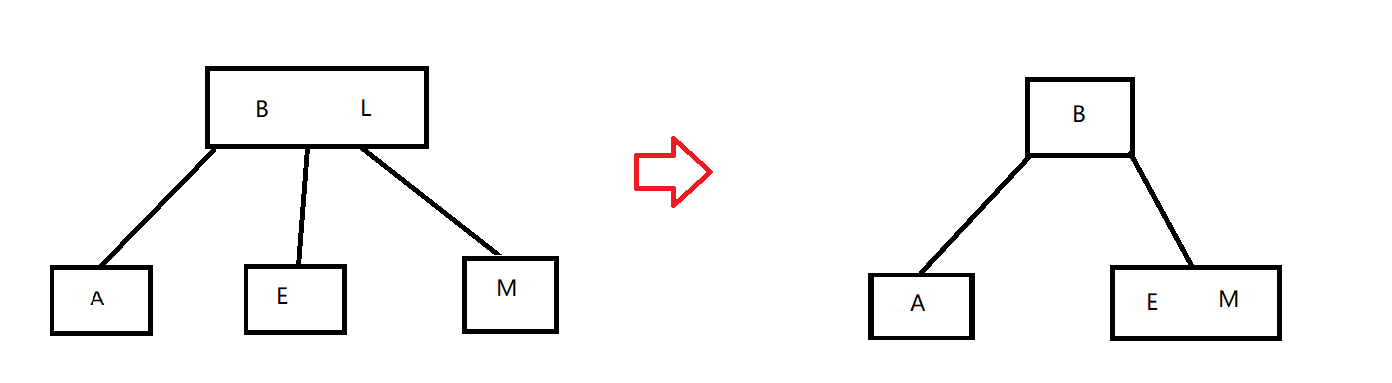
2-3查找树的删除与AVL tree删除过程差不多,只不过比AVL tree的情况更多而已。我们有如果策略,我们可以在被删除的节点处,找到左侧的最大值,或右侧的最小值用以顶替被删除的值。如
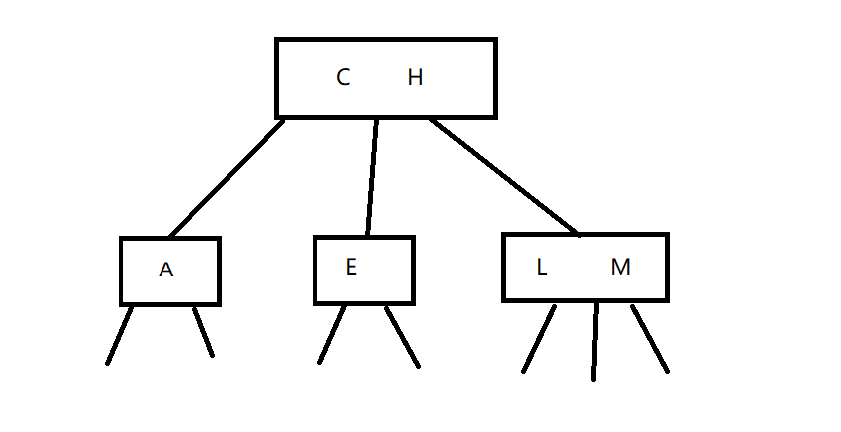
假设我们要删除节点C,则有
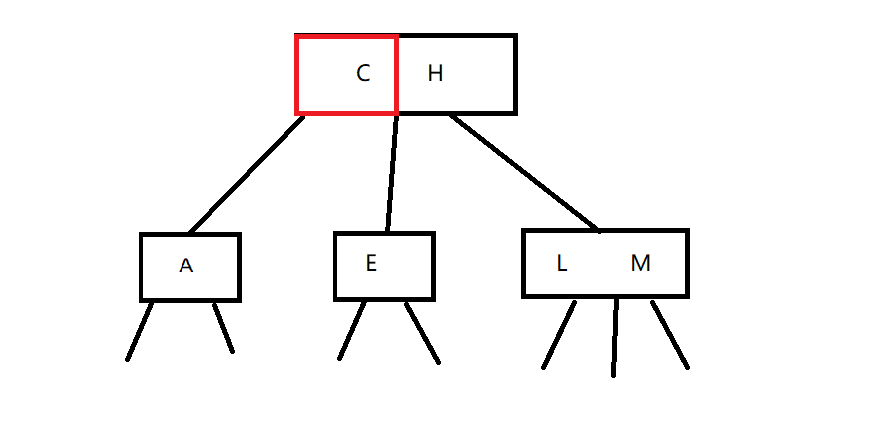
在删除C后,我们可以从左子树中寻找最大节点或从右子树中寻找最小节点来替代节点C。即我们有节点树
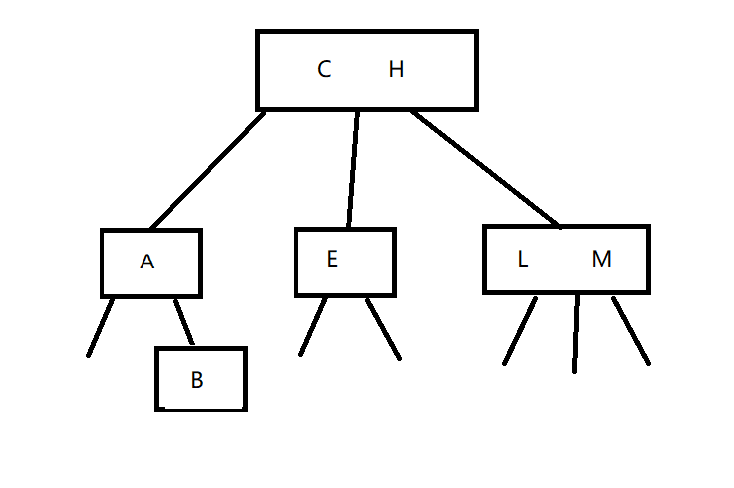
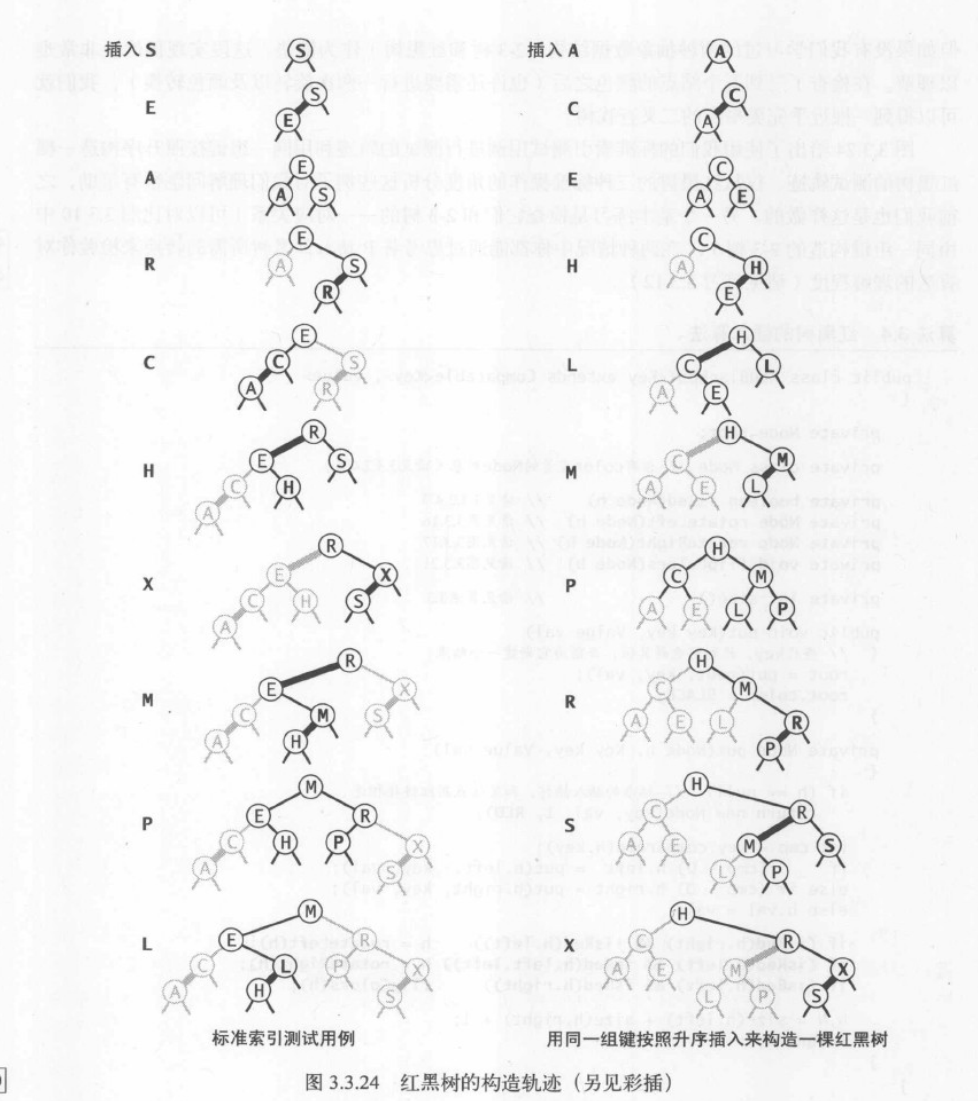
红黑二叉查找树
红黑二叉查找树其本质是用额外的信息来表示2-3树。即用标准二叉树(完全由2-结构构成)和一些额外的信息(替换3-结点)来表示2-3树。我们将树中的链接分为两种类型:红链接将两个2-结点连接起来构成一个3-结点,黑链接则是2-3树中普通链接。即我们将3-结点表示为由一条左斜的红色链接(两个2-结点其中之一是另一个左子结点)相连的两个结点。
红黑树的另一种定义
红黑树的另一种定义是含有红黑链接并满足以下条件的二叉查找树:
- 红链接均为左链接
- 没有任何一个结点同时和两条红链接相连
- 该树是完美黑色平衡的,即任意空链接到根结点的路径数量相同
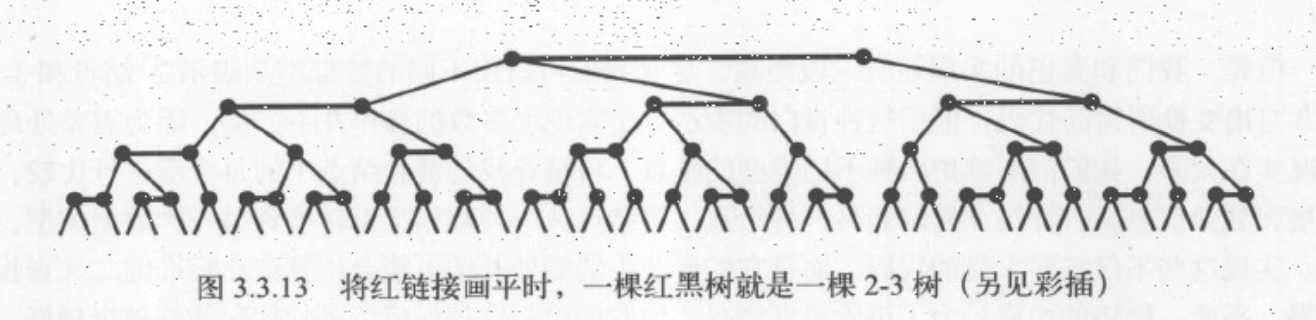
颜色表示
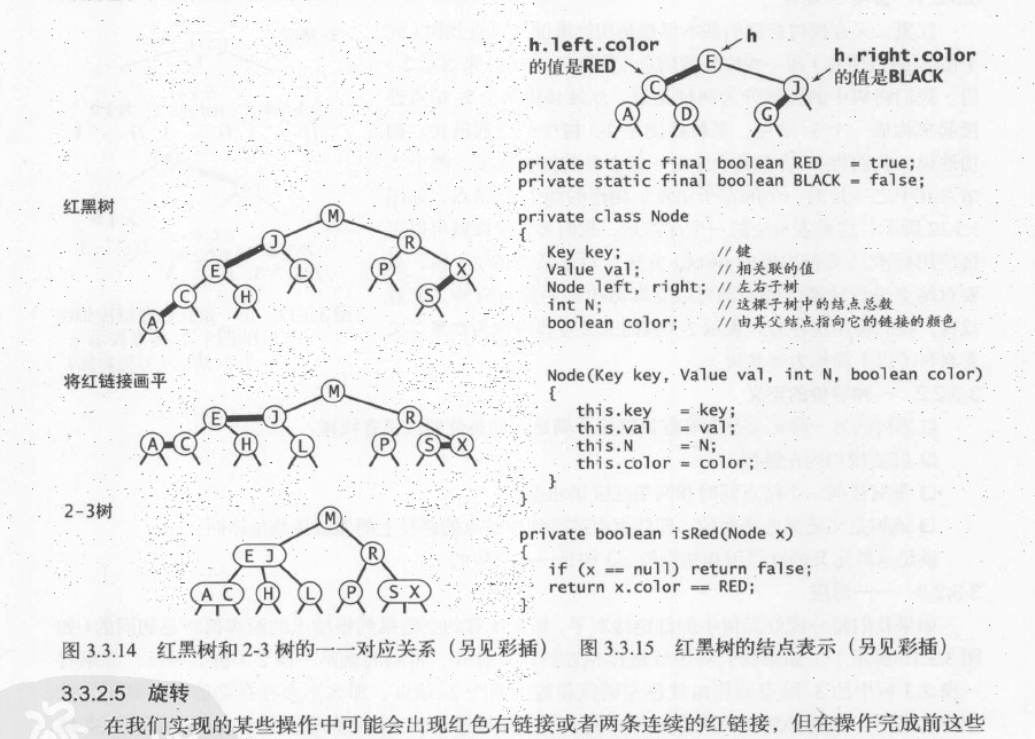
每个结点都只会有一条指向自己链接(从它的父结点指向它),我们将链接的颜色保存在给结点的Node数据类型的布尔变量中。如果指向它的链接是红色的,那么该变量为true,黑色为false。则我们有结构定义
1
2
3
4
5
6
7
| class Node{
Key key;//键
Value val;//相关联的值
Node Left,Right;//左右子树
int N;//这棵树的总结点数
boolean color;//其父结点指向它链接的颜色
}
|
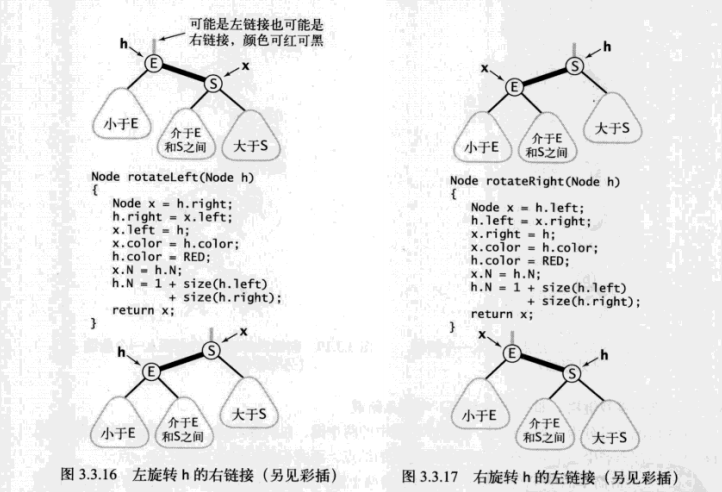
旋转
我们在实现某些操作中可能会出现红色右链接或都两条连续的红色链接,但在操作完成前这些情况都会被小心地旋转并修复。旋转操作会改变红链接的指向。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| //左旋转
Node rotateLeft(Node h){
Node x=h.right;//保存右子节点
h.right=x.left;
x.left=h;
x.color=h.color;
h.color=RED;
x.N=h.N;
h.N=1+size(h.left)+size(h.right);
return x;
}
//右旋转
Node rotateRight(Node h){
Node x=h.left;
h.left=x.right;
x.right=h;
x.color=h.color;
h.color=RED;
x.N=h.N;
h.N=1+size(h.left)+size(h.right);
return x;
}
|
向树底部的2-结点插入新建
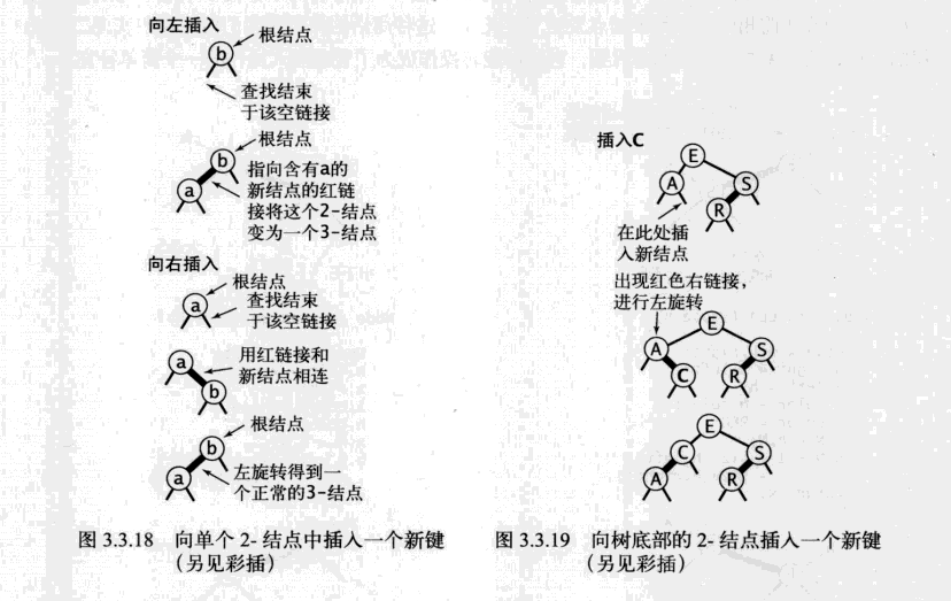
向一棵双键树(即一个3-结点)中插入新键
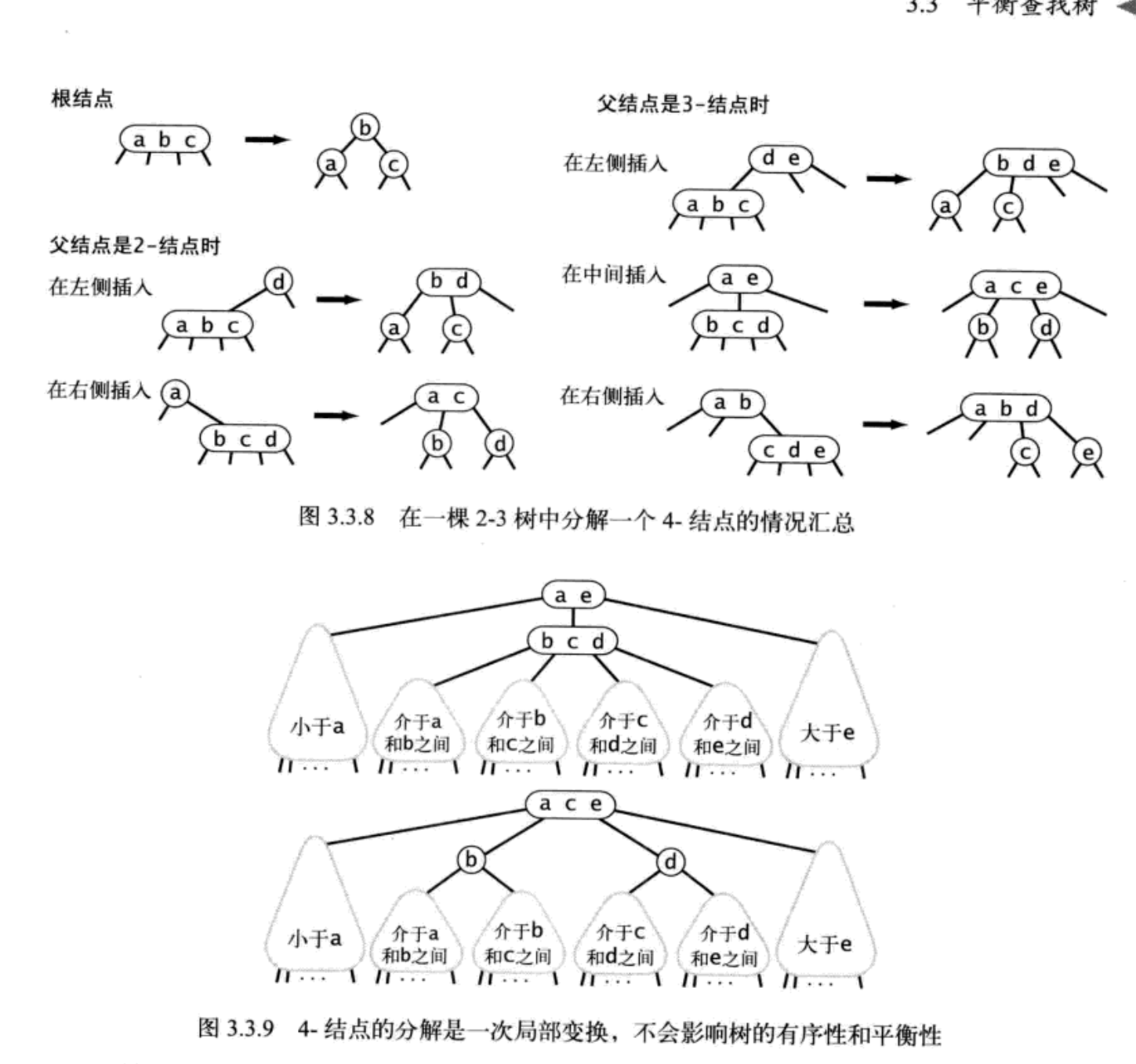
可分为三种子情况:新建小于树中的两个键,在两者之间,或是大于树中的两个键。每种情况都会产生一个同时连接到两条红链接的结点,我们的目标就是修正这一点。
- 当新键大于原树中的两个键,因此会被连接到3-结点的左路链接。此时树是平衡的,根结点为中间大小的键。它有两条红链接分别和较小和较大的结点相连。如果我们将两条链接的颜色都由红变黑,那么我们会得到一棵由三个结点组成,高为2的平衡树。见下图。
- 如果新键小于原树中的两个键,它会被链接到最左边的空链接,会产生两条连续的红链接,此时我们只需要将上层的红链接右旋转即可得到第一种情况。
- 如果新键介于原树中的两个键之间,这又会产生两条连续的红链接,一条红色左链接接一条红色右链接,只需要将下层的红链接左旋转即可得到第二种情况。
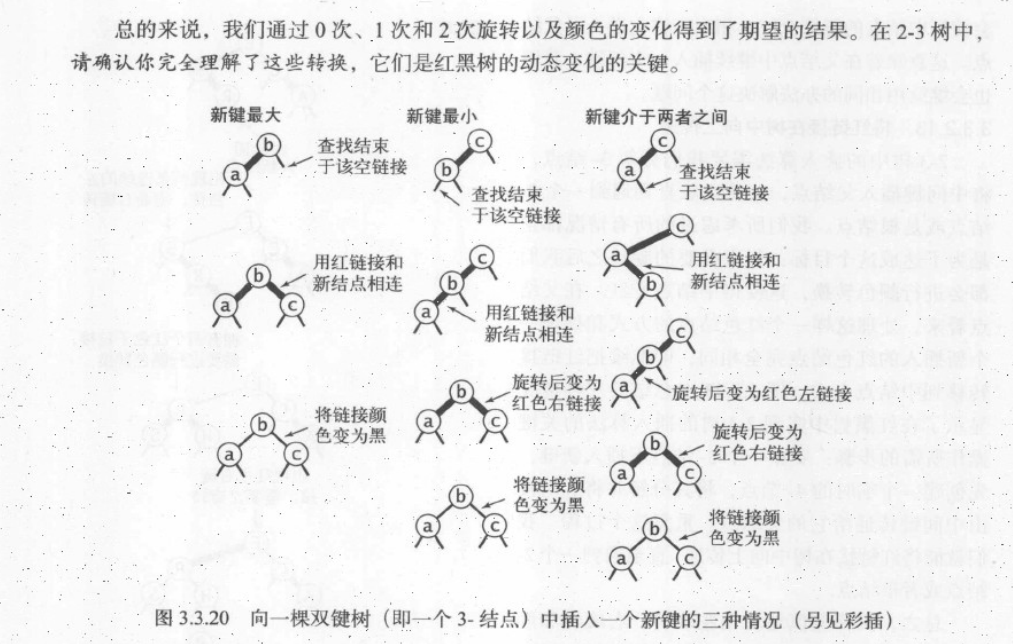
颜色转换
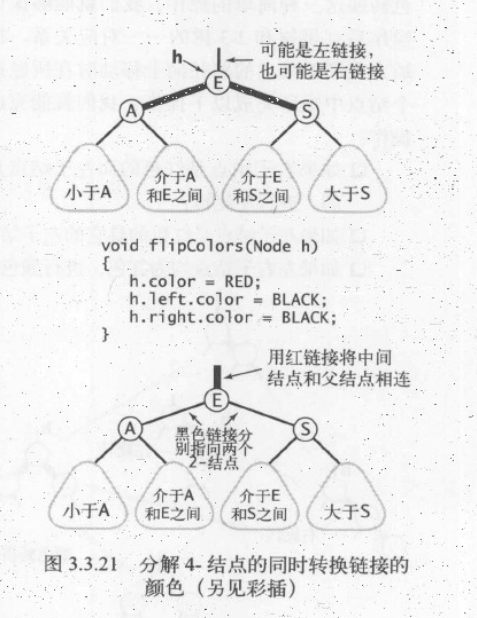
我们使用一个方法filpColors()来转换一个结点的两个红色子结点的颜色。除了将子结点的颜色由红变黑之外,还需要将父结点的颜色由黑变红。
1
2
3
4
5
| void filpColors(Node h){
h.color=RED
h.left.color=BLACK
h.right.color=BLACK
}
|
注:根结点总是黑色的
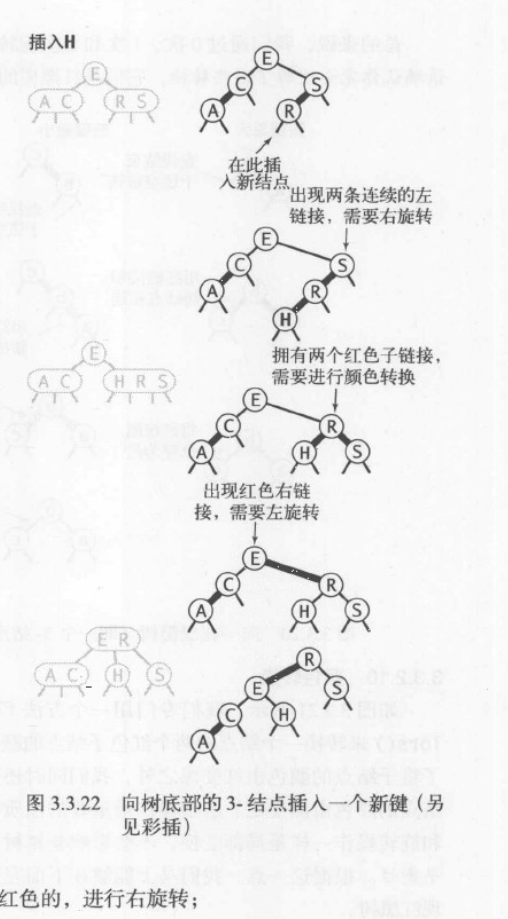
向树底部的3-结点插入新键
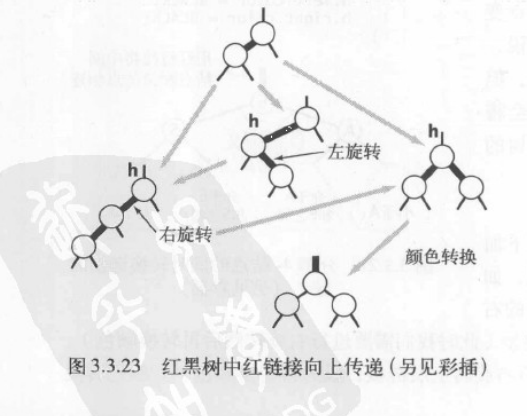
在沿着插入点到根结点的路径向上移动时在所经过每个结点中顺序完成以下操作,我们能完成插入操作。
- 如果右子结点是红色的而左子结点是黑色的,进行左旋转。
- 如果左子结点是红色的且它的左子结点也是红色的,进行右旋转。
- 如果左右子结点均为红色,进行颜色转换。
插入实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| public class RedBlackBST<Key extends Comparable<Key>,Value>{
private Node root;
private class Node;
private boolean isRed(Node h);
private Node rotateLeft(Node h);
private Node rotateRight(Node h);
private void filpColors(Node h);
private int size();
public void put(Key key,Value val){
root=put(root,key,val);
root.color=Black;
}
public Node put(Node h,Key key,Value val){
if(h==null){
return new Node(key,val,1,RED);
}
int cmp=key.compareTo(h.key);
if(cmp<0)
h.left=put(h.left,key,val);
else if(cmp>0)
h.right=put(h.right,key,val);
else
h.val=val;
if(isRed(h.right)&&!isRed(h.left))
h=rotateLeft(h);
if(isRed(h.left)&&isRed(h.left.left)){
h=rotateRight(h);
}
if(isRed(h.left)&&isRed(h.right))
flipColors(h);
h.N=size(h.left)+size(h.right)+1;
return h;
}
}
|
自顶向下的2-3-4树
2-3-4树的插入算法,2-3-4树中允许存在我们以前见过的4-结点。它的插入算法沿查找路径向下进行变换是为了保证当前结点不是4-结点(这样树底才有空间来插入新的键),沿查找路径向上进行变换是为了将之前创建的4-结点配平。
- 如果根结点是4-结点,则将它分解成三个2-结点,使得树高加1。
- 在向下查找的过程中,如果遇到一个父结点为2-结点的4-结点,将4-结点分解为两个2-结点并将中间键传递给它的父结点,使得父结点变成一个3-结点。
- 在向下查找的过程中,如果遇到一个父结点为3-结点的4-结点,我们将4-结点分解为两个2-结点并将中间键传递给它的父结点,使得父结点变成一个4-结点。
注:该算法在查找要删除的值的过程进行变换,使得只保留2-和3-结点,并且要删除的值必在一棵2-结点中(不包括父结点),这样做可以删除值之后能较好进行插入。
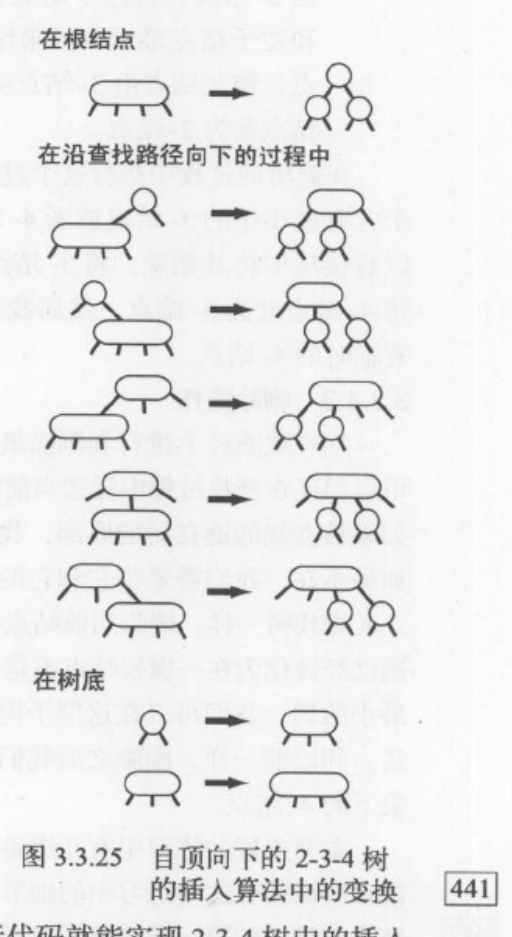
在实现这个算法,我们需要
- 将4-结点表示为由三个2-结点组成的一棵平衡的子树,根结点和两个子结点都用红链接相连
- 在向下的过程中分解所有4-结点并进行颜色转换
- 和插入操作一样,在向上的过程中用旋转将4-结点进行配平
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public void put(Key key,Value val){
root=put(root,key,val);
root.color=Black;
}
public Node put(Node h,Key key,Value val){
if(h==null){
return new Node(key,val,1,RED);
}
if(isRed(h.left)&&isRed(h.right))
flipColors(h);
int cmp=key.compareTo(h.key);
if(cmp<0)
h.left=put(h.left,key,val);
else if(cmp>0)
h.right=put(h.right,key,val);
else
h.val=val;
if(isRed(h.right)&&!isRed(h.left))
h=rotateLeft(h);
if(isRed(h.left)&&isRed(h.left.left)){
h=rotateRight(h);
}
h.N=size(h.left)+size(h.right)+1;
return h;
}
|
删除最小键
我们注意到从树底部的3-结点中删除键是很简单的,但是2-结点则不然。从2-结点中删除一个键会留下一个空结点,一般我们会将它替换成一个空链接,我们沿着左链接如下进行变换,确保当前结点不是2-结点(可能是3-结点,也可能是4-结点)。
首先根结点可能有两种情况(见下图)。
- 如果根是2-结点且它的两个子结点都是2-结点,我们可以直接将这三个结点变成一个4-结点。
- 如果根为2-结点且左子结点是2-结点,但右子结点不2-结点,则我们需要从右子结点中借一个结点过来。
在沿着左链接如下的过程中,需要保证以下情况之一成立(见下图)。
- 如果当前结点的左子结点不是2-结点,完成。
- 如果当前结点的左子结点是2-结点而它亲兄弟结点不是2-结点,将左子结点的兄弟结点中的一个键移动到左子结点中。
- 如果当前结点的左子结点和它的亲兄弟结点都是2-结点,将左子结点、父结点中的最小键和左子结点最近的兄弟结点合并为一个4-结点,使父结点由3-结点变为2-结点或由4-结点变为3-结点
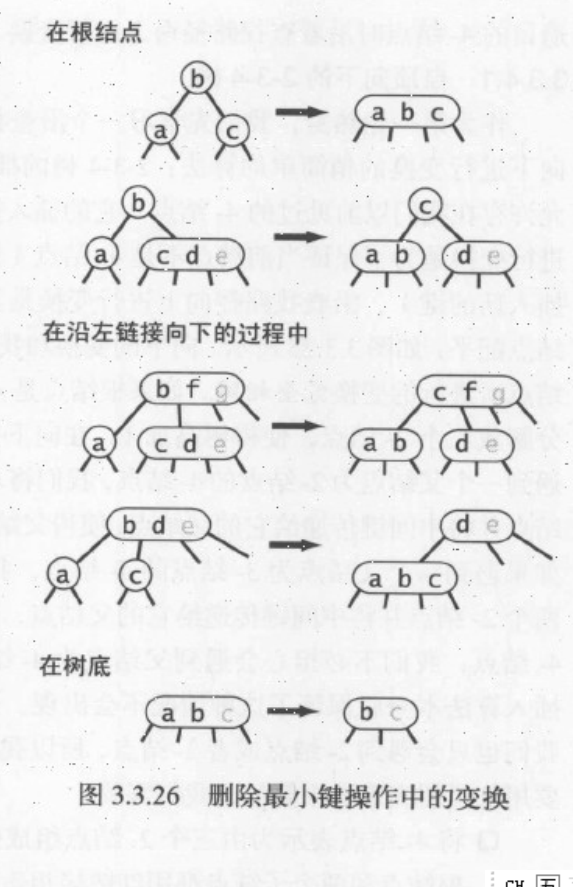
在遍历的过程中执行这个过程,最后能够得到一个含有最小键的3-结点或4-结点,然后我们可以直接从中将其删除,将3-结点变为2-结点,或者将4-结点变为3-结点,然后再回头向上分解所有临时的4-结点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| private Node moveRedLeft(Node h){
flipColors(h);
if(isRed(h.right.left)){
h.right=rotateRight(h.right);
h=rotateLeft(h);
}
return h;
}
public void deleteMin(){
if(!isRed(root.left)&&!isRed(root.right)){
root.color=RED;
}
root=deleteMin(root);
if(!isEmpty())
root.color=BLACK;
}
private Node deleteMin(Node h){
if(h.left==null)
return null;
if(!isRed(h.left)&&!isRed(h.left.left)){
h=moveRedLeft(h);
}
h.left=deleteMin(h.left);
return balance(h);
}
private Node balance(Node h){
if(isRed(h.right))
h=rotateLeft(h);
if(isRed(h.right)&&!isRed(h.left))
h=rotateLeft(h);
if(isRed(h.left)&&isRed(h.left.left)){
h=rotateRight(h);
}
if(isRed(h.left)&&isRed(h.right))
flipColors(h);
h.N=size(h.left)+size(h.right)+1;
return h;
}
|
删除最大键
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| private Node moveRedRight(Node h){
filpColors(h);
if(!isRed(h.left.left)){
h=rotateRight(h);
}
return h;
}
public void deleteMax(){
if(!isRed(root.left)&&!isRed(root.right)){
root.color=RED;
}
root=deleteMax(root);
if(!isEmpty())
root.color=BLACK;
}
public Node deleteMax(){
if(!isRed(root.left)&&!isRed(root.right))
root.color=RED;
root=deleteMax(root);
if(!isEmpty())
root.color=BLACK;
}
private Node deleteMax(Node h){
if(isRed(h.left))
h=rotateRight(h);
if(h.right==null)
return null;
if(!isRed(h.right)&&!isRed(h.right.left))
h=moveRedRight(h);
h.right=deleteMax(h.right);
return blance(h);
}
|
删除操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public void delete(Key key){
if(!isRed(root.left)&&!isRed(root.right))
root.color=RED;
root=delete(root,key);
if(!isEmpty())
root.color=BLACK;
}
private Node delete(Node h,Key key){
if(key.compareTo(h.key)<0){
if(!isRed(h.left)&&!isRed(h.left.left))
h=moveRedLeft(h);
h.left=delete(h.left.key);
}else{
if(isRed(h.left))
h=rotateRight(h);
if(key.compareTo(h.key)==0&&(h.right==null)){
return null;
}
if(!isRed(h.right)&&!isRed(h.right.left)){
h=moveRedRight(h);
}
if(key.compareTo(h.key)==0){
h.val=get(h.right,min(h.right).key);
h.key=min(h.right).key;
h.right=deleteMin(h.right);
}
else
h.right=delete(h.right,key);
}
return balance(h);
}
|
RB-Tree的节点设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| typedef bool _rb_tree_color_type;
typedef _rb_tree_color_type _rb_tree_red=false;
typedef _rb_tree_color_type _rb_tree_black=true;
struct _rb_tree_node_base{
typedef _rb_tree_color_type color_type;
typedef _rb_tree_node_base* base_ptr;
color_type color;
base_ptr parent;
base_ptr left;
base_ptr right;
static base_ptr minimum(base_ptr x){
while(x->left!=0) x=x->left;
return x;
}
static base_ptr maximum(base_ptr x){
while(x->right!=0) x=x->right;
return x;
}
};
template<class Value>
struct _rb_tree_node:public _rb_tree_node_base{
typedef _rb_tree_node<Value>* link_type;
Value value_field;
}
|
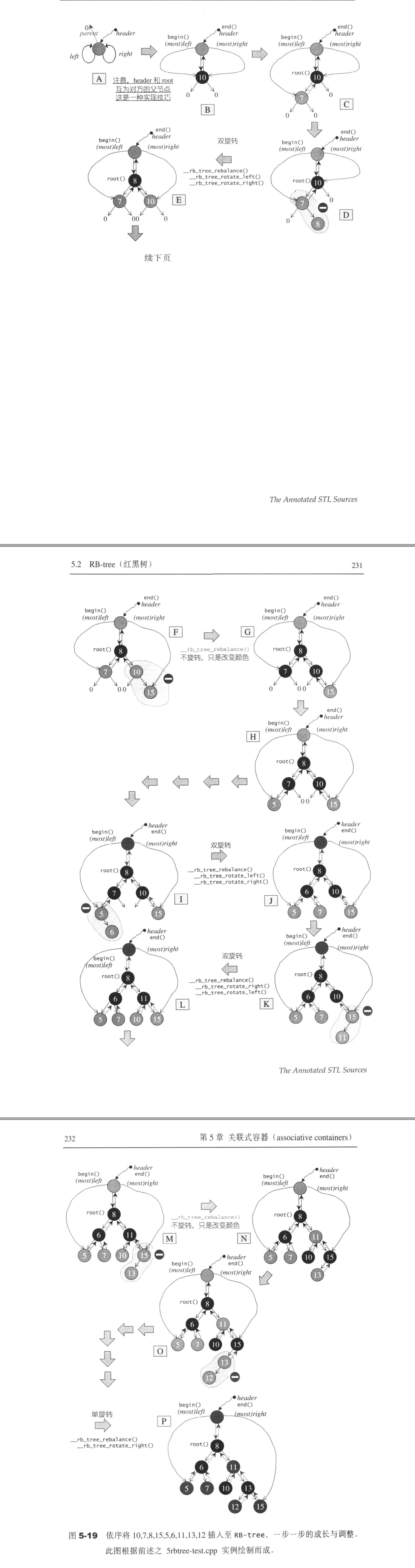
RB-tree的数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| template<class Key,class Value,class KeyOfValue,class Compare,class Alloc=alloc>
class rb_tree{
protected:
size_type node_count;
link_type header;
Compare key_compare;
typedef simple_alloc<rb_tree_node,Alloc> rb_tree_node_allocator;
link_type get_node(){ return rb_tree_node_allocator::allocate();}
void init(){
header=get_node();
color(header)=_rb_tree_red;
root()=0;
leftMost()=header;
rightMost()=header;
}
}
|
set
set的特性是所有元素都会根据元素的键值自动被排序。set的元素不像map那样可以同时拥有有实值(value)和键值(key)。set元素的键值就是实值,实值就是键值,set不允许两个元素有相同的键值。
我们无法通过set的迭代器去改变set的元素。因为set::iterator 被 定义为底层RB-tree的const_iterator。
由于RB-tree是一种平衡二叉树,自动排序效果很不错,所以标准的STL set即以RB-Tree的为底层机制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| template<class Key,class Compare=less<Key>,class Alloc=alloc>
class set{
public:
typedef Key key_type;
typedef Key value_type;
typedef Compare key_compare;
typedef Compare value_compare;
private:
typedef rb_tree<key_type,value_type,identity<value_type>,key_compare,Alloc>rep_type;
rep_type t;
public:
typedef typename rep_type::const_pointer pointer;
typedef typename rep_type::const_pointer const_pointer;
typedef typename rep_type::const_reference reference;
typedef typename rep_type::const_reference const_reference;
typedef typename rep_type::const_iteraotr iterator;
typedef typename rep_type::const_iterator const_iterator;
typedef typename rep_type::const_reverse_iterator reverse_iterator;
typedef typename rep_type::const_reverse_iterator const_reverse_iterator;
typedef typename rep_type::size_type size_type;
typedef typename rep_type::difference_type difference_type;
set():t(Compare()){}
explicit set(const Compare&comp):t(comp){}
template<class InputIterator>
set(InputIterator first,InputIterator last):t(Compare()){
t.insert_unique(first,last);
}
template<class InputIterator>
set(InputIterator first,InputIterator last,const Compare&comp):t(comp){
t.insert_unique(first,last);
}
set<const set<Key,Compare,Alloc>&x>:t(x.t){}
set<Key,Compare,Alloc>&operator=(const set<Key,Compare,Alloc>&x){
t=x.t;
return *this;
}
key_compare key_comp()const {retur t.key_comp();}
value_compare value_comp()const {return t.key_comp();}
iterator begin()const {return t.begin();}
iterator end()const {return t.end();}
reverse_iterator rbegin()const {return t.rbegin();}
reverse_iterator rend()const {return t.rend();}
bool empty()const {return t.empty();}
size_type size()const {return t.size();}
size_type max_size()const {return t.max_size();}
void swap(set<Key,Compare,Alloc>&x) {t.swap(x.t); }
typedef pair<iterator,bool>pair_iterator_bool;
pair_iterator_bool insert(const value_type&x){
pair<typename rep_type::iterator,bool>p=t.insert_unique(x);
return pair<iterator,bool>(p.first,p.second);
}
size_type erase(const key_type&x){
return x.erase(x);
}
size_type count(const key_type&x)const{
return t.count(x);
}
}
|
set底层运用rb-tree进行数据的插入、删除和查找 。
map
map的特性是,所有元素都会根据元素的键值自动被排序。map的所有元素都是pair,同时拥有实值和键值,pair的第一元素被视为键值,第二元素被视为实值。Map不允许两个元素拥有相同的键值。
1
2
3
4
5
6
7
8
9
10
11
|
template<class T1,class T2>
struct pair{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
piar():first(T1()),second(T2()){}
pair(const T1&a,const T2&b):first(a),second(b){}
}
|
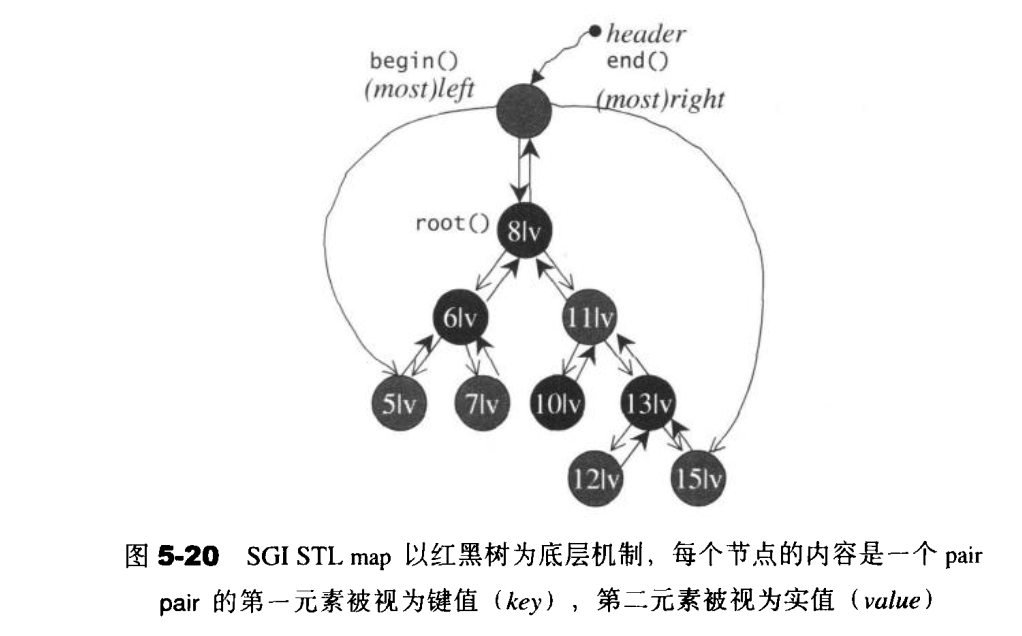

multiSet

multiMap

hashtable(哈希表)
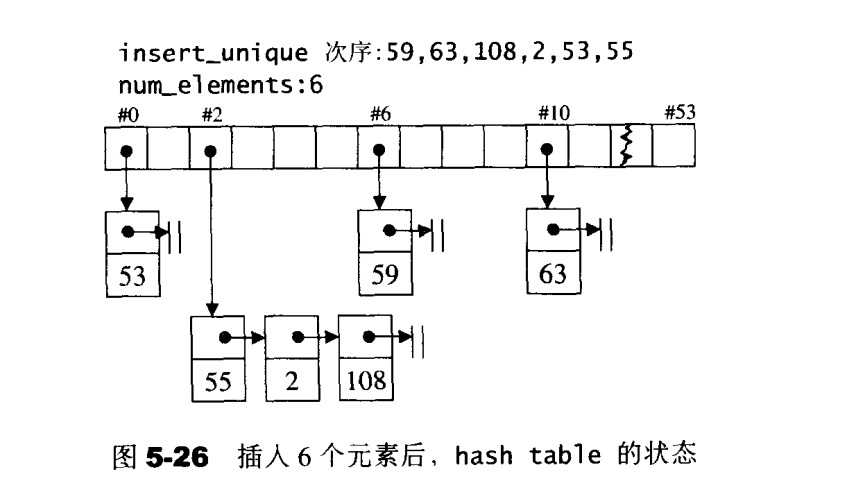
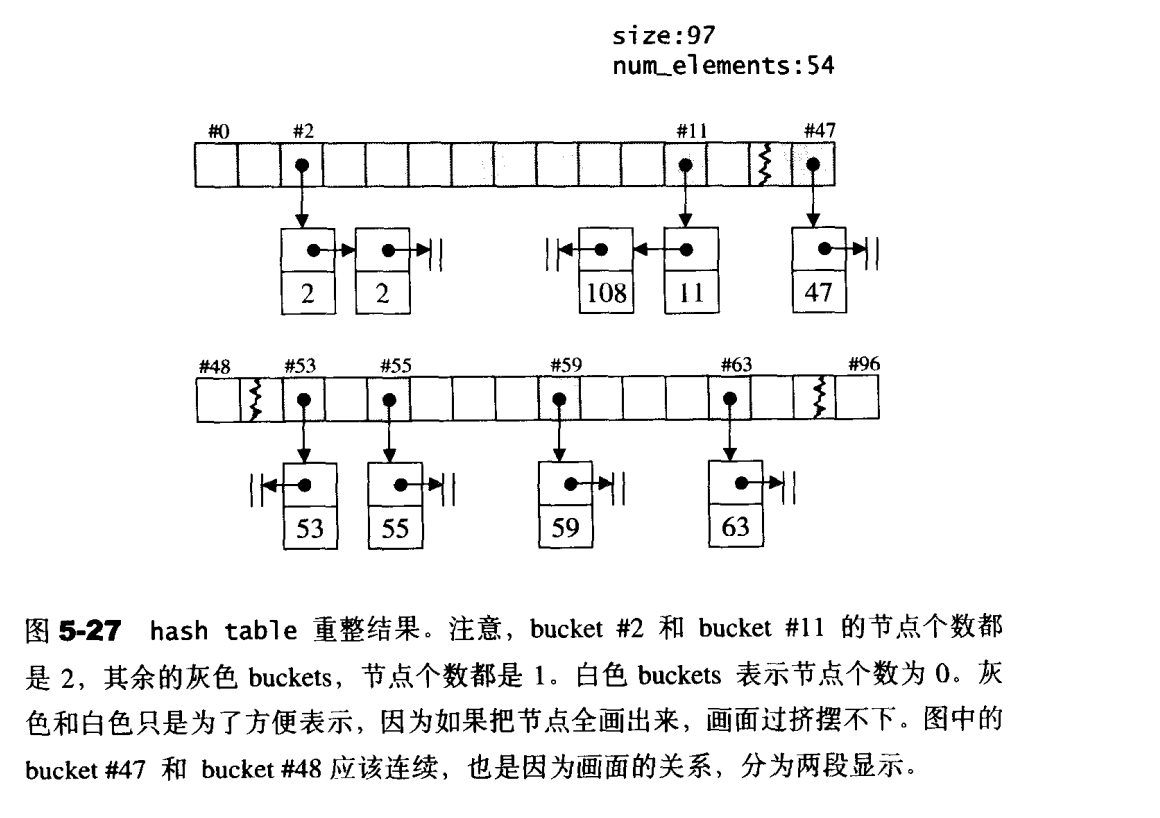
hash table可提供对任何有名项的存取操作和删除操作。由于操作对象是有名项,所以hash table也可被视为一个字典结构,这种结构的用意在于提供常数时间之基本操作。
线性探测
负载系数 ,指元素个数除以表格大小。负载系统永远在0-1之间——除非采用开链策略。
若当hash function计算出某个元素的插入位置,而该位置上空间已不再可用时,我们需要循序往下一一寻找(如果到达尾端,就绕到头部继续寻找),直到找到一个可用空间为止。只要表格足够大,总是能够找到一个可以插入的空间。而元素的删除,必须要采用惰性删除,也就只标记删除记号,实际删除操作则待表格重新整理时再进行——这是因为hash table中的每一个元素不仅表述它自己,也关系到其它元素的排列。

二次探测
二次探测主要用来解决线性探测频繁碰撞的问题。其方程为
如果hash function 计算出新元素的位置为H,而该位置实际上已被使用,那么我们依序尝试$H+1^2$,
,。

如果我们假设表格大小为质数,而且永远保持负载系统在0.5以下(也就是超过0.5就重新配置并重新整理表格),那么就可确实每插入一个新元素所需要探测次数不多于2。
二次探测可以消除主集团(频率碰撞),即可能造成次集团:两个元素经hash funciton计算出来的位置若相同,则插入时所探测的位置也相同,形成某种浪费。
开链
开链是在每一个表格元素中维护一个list:hash function 为我们分配某一个List,然后我们在那个List身上执行元素的插入、搜寻、删除等操作。
hash table的桶子与节点
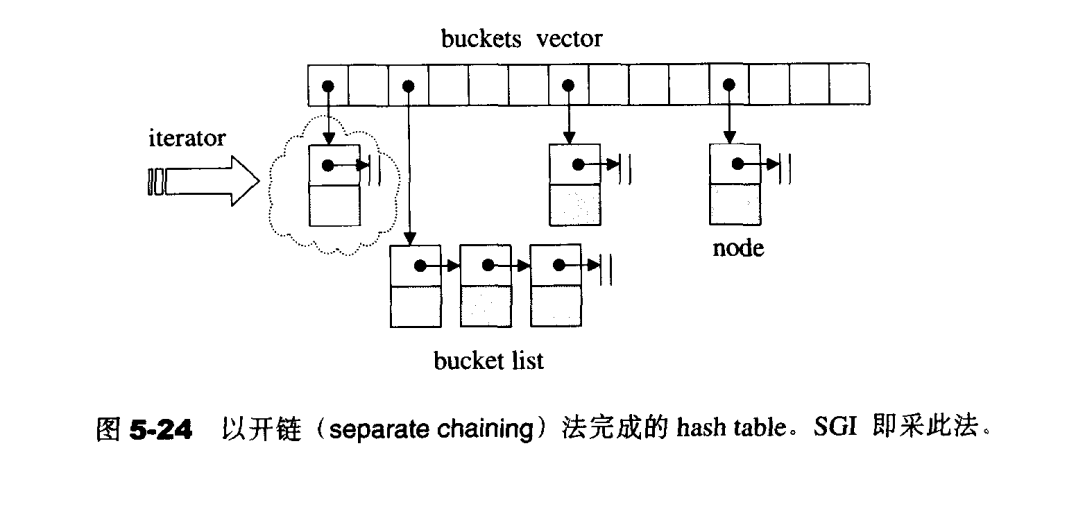
1
2
3
4
5
6
|
template<class Value>
struct _hashtable_node{
_hashtable_node*next;
Value value;
}
|
hashtable的迭代器

1
2
3
4
5
6
7
8
9
10
11
12
13
| template<class V,class K,class HF,class ExK,class EqK,class A>
_hashtable_iterator<V,K,HF,ExK,EqK,A>&
_hashtable_iterator<V,K,HF,ExK,EqK,A>::operator++(){
const node*old=cur;
cur=cur->next;
if(!cur){
size_type bucket=ht->bkt_num(old->val);
while(!cur&&++bucket<ht->buckets.size())
cur=ht->buckets[bucket];
}
return *this;
}
|
hashtable的数据结构


hashtable的构造与内存管理

插入操作(insert)与表格重整(resize)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
pair<iterator,bool>insert_unique(const value_type&obj){
resize(num_elements+1);
return insert_unique_noresize(obj);
}
template<class V,class K,class HF,class Ex,class Eq,class A>
void hashtable<V,K,HF,Ex,Eq,A>::resize(size_type num_elements_hint){
const size_type old_n=buckets.size();
if(num_elements_hint>old_n){
const size_type n=next_size(num_elements_hint);
if(n>old_n){
vector<node*,A>temp(n,(node*)0);
for(size_type bucket=0;bucket<old_n;bucket++){
node*first=buckets[bucket];
while(first){
size_type new_bucket=bkt_num(first->val,n);
buckets[bucket]=first->next;
first->next=temp[new_bucket];
temp[new_bucket]=first;
first=buckets[bucket];
}
}
bucket.swap(temp);
}
}
}
|
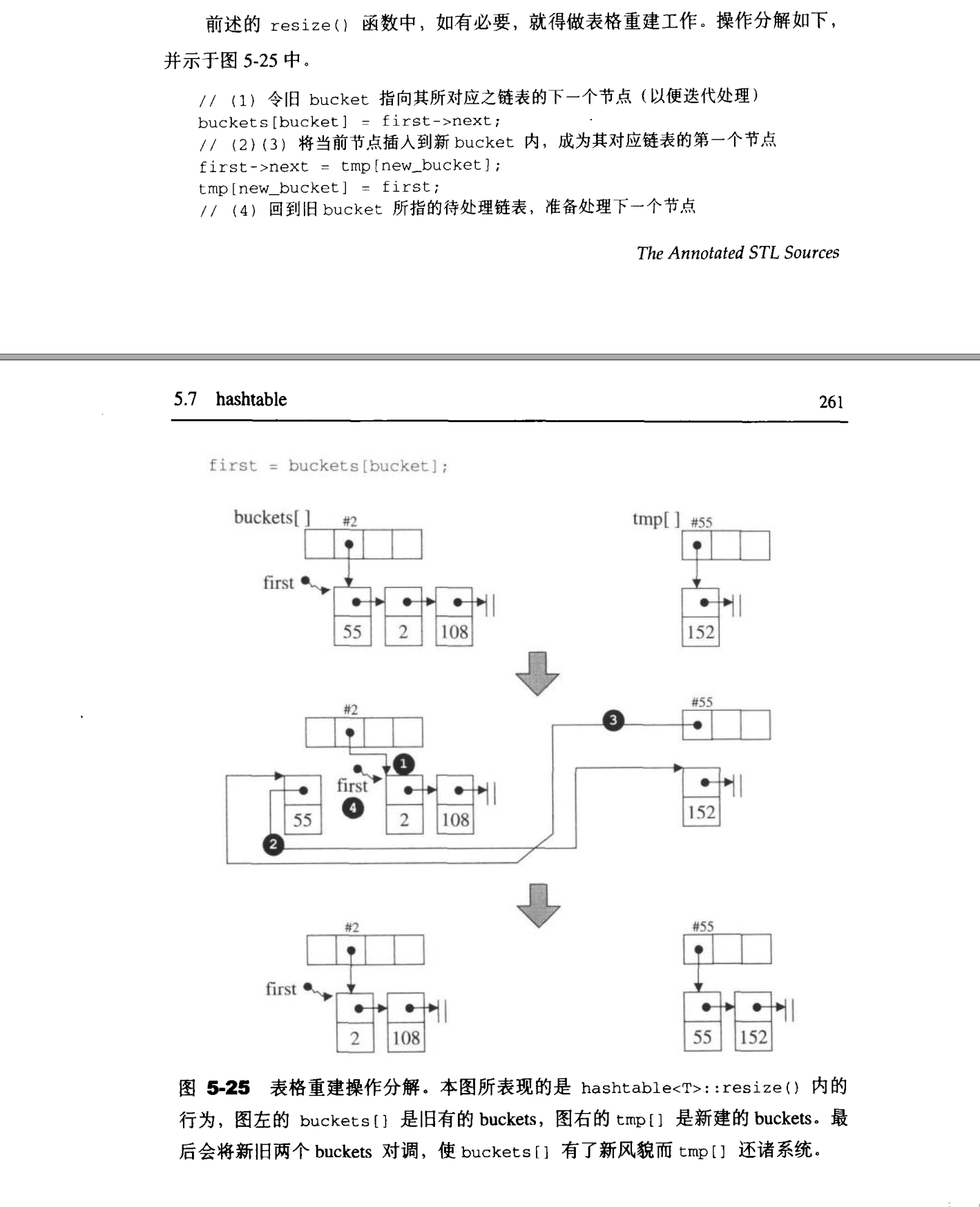
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
template<class V,class K,class HF,class Ex,class Eq,class A>
pair<typename hashTable<V,K,HF,Ex,Eq,A>::iterator,bool>
hashtable<V,K,HF,Ex,Eq,A>::insert_unique_noresize(const value_type&obj){
const size_type n=bkt_num(obj);
node*first=buckets[n];
for(node*cur=first;cur;cur=cur->next){
if(equals(get_key(cur_val),get_key(obj)))
return pair<iterator,bool>(iterator(cur,this),false);
}
node*temp=new_node(obj);
temp->next=first;
buckets[n]=temp;
++num_elements;
return pair<iterator,bool>(iterator(temp,this),true);
}
|


判知元素的落脚处

复制和整体删除


仿函数
仿函数是一个“行为类似函数”的对象

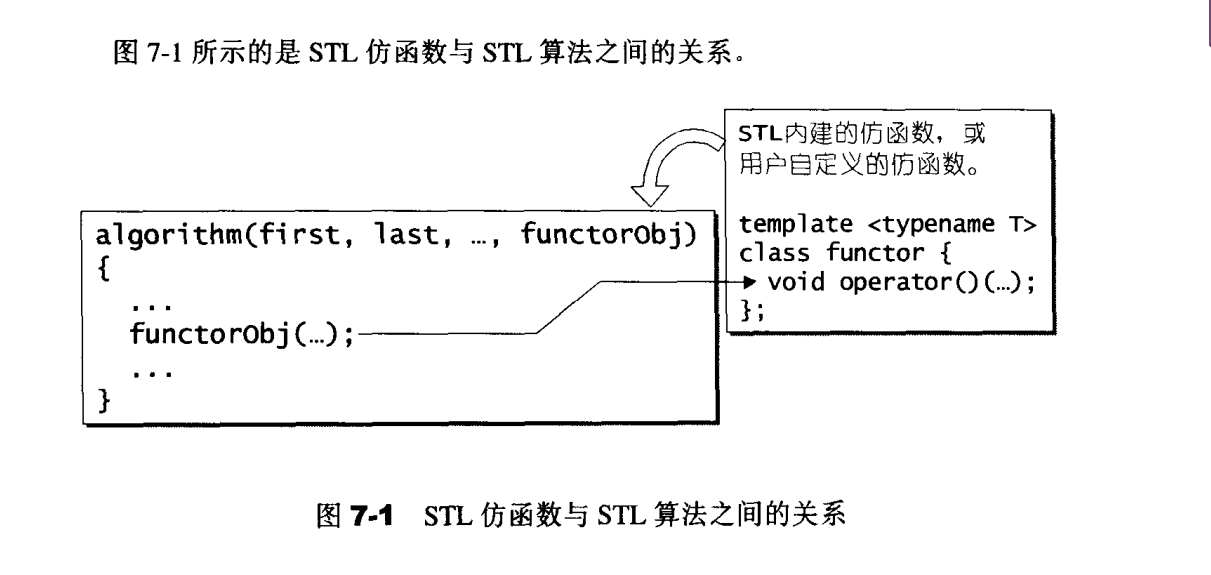

可配接的关系
若仿函数要融入STL中,则需要有配接能力。
unary_function
unary_faction 用来呈现一元函数的参数型别和回返值型别 。
1
2
3
4
5
| template<class Arg,class Result>
struct unary_function{
typedef Arg argument_type;
typedef Result result_type;
}
|
一旦某个仿函数继承了unary_function,其用户便可以取得这样的仿函数的参数型别,并以相同手法取得其回返值型别。
1
2
3
4
5
6
| template<class T>
struct negate:public unary_function<T,T>{
T operator()(const T&x)const{
return -x;
}
}
|
binary_function
binary_function用来呈现二元函数的第一参数型别、第二参数型别以及返回值型别。
1
2
3
4
5
6
7
8
9
10
11
12
13
| template<class Arg1,class Arg2,class Result>
struct binary_function{
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
};
template<class T>
struct plus:public binary_function<T,T,T>{
T operator()(const T&x,const T&y)const{
return x+y;
}
}
|
算术类仿函数


关系运算类仿函数

逻辑类仿函数
