本文为基于CNN的代码查重模型所涉及的知识点的总结。该论文主是通过利用卷积神经网络来进行模型的构建,经过一定数量的数据训练使得模型在进行代码查重具有一定的准确性。该流程主要分成三个部分,一、代码文本预处理,二、数据输入进模型并得到向量,三、文本的相似度计算。
相关技术介绍
词嵌入
词嵌入原本是用来表示自然语言的向量表示方法,词嵌入可以使得自然语言文本映射成为一个向量矩阵,这会使得词通过词嵌入映射变得更加有含义,可以通过词嵌入映射的向量进行词的类比。其中词进行映射成嵌入矩阵的流程如下图所示
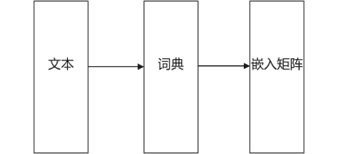
其中词典为文本中的词的类别映射成的(词,数字)元组,使得已经包括进行词典的词,可以再次映射到相同的数字。如有文本,周杰伦/唱/本草纲目,我们可以得构建的词典为{“周杰伦”:1, “和”:2, “本草纲目”:3},这样我们就构建起了词典,下次再次出现“周杰伦”,我们就把这个词映射成为1,出现“本草纲目”,会把这个映射成3,若出现新的不在词典中的词会接着进行映射。当然,上面对于文本是进行了分词操作,如果没有使用分词操作,会进行单个字符的映射来构建词典,总得来说,词典把文本映射成数字,再把数字送入嵌入层来得到嵌入矩阵。对于嵌入层来说,运算过程图2所示
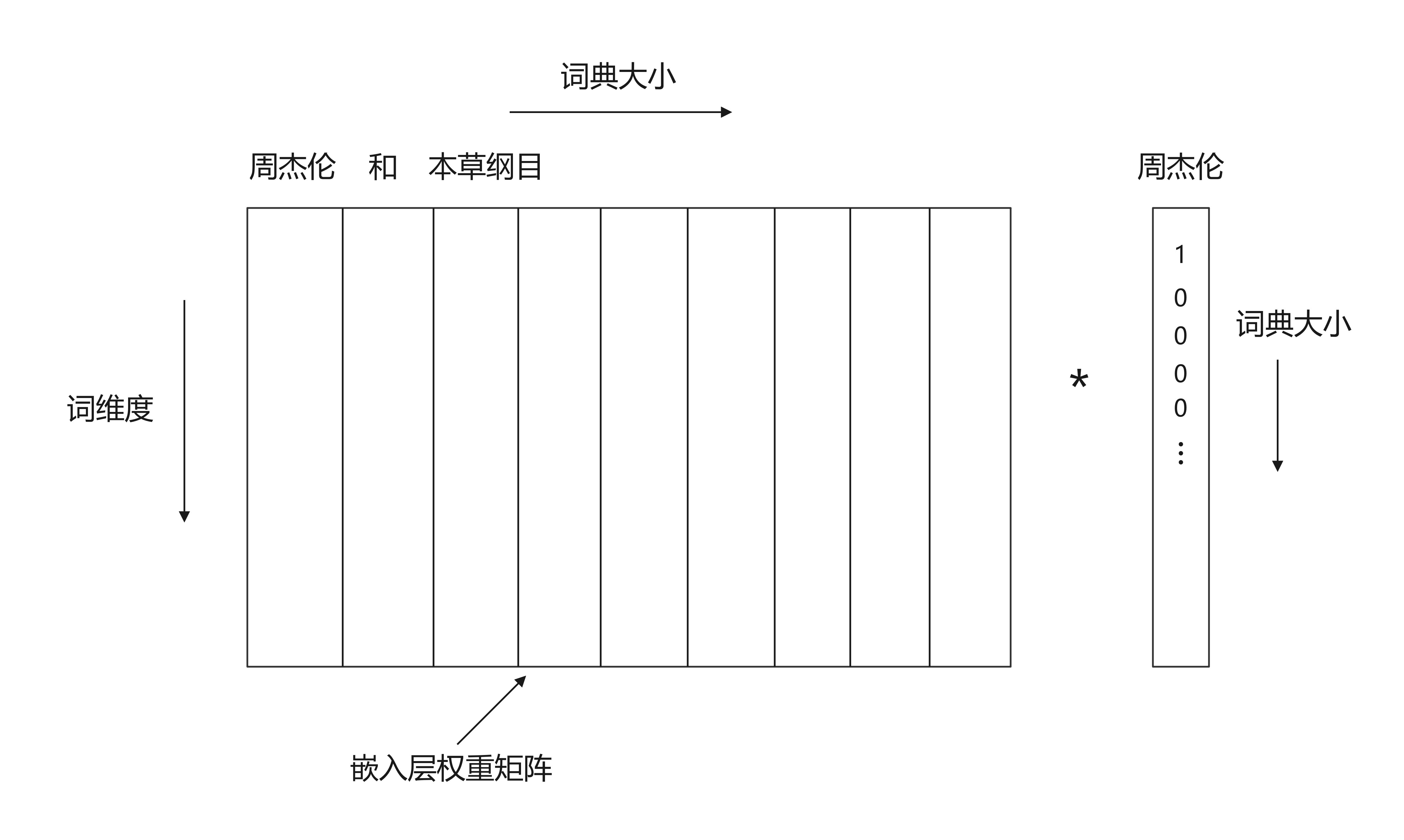
我们可以从上图可以看出两个矩阵进行相乘可以得到“周杰伦”的嵌入层权重向量,且权重向量为词维度,故整个嵌入层的权重矩阵为词典大小*词维度。
神经网络
神经网络结构
我们把多个神经元相互进行连接,即可得到一个神经网络。如图3如示。
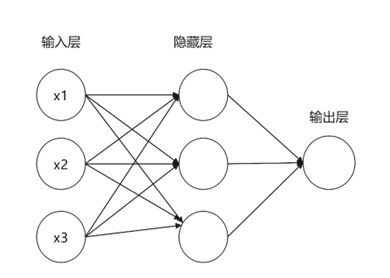
这是一个简易的神经网络图,由三层组成,分别为输入层、隐藏层、输出层组成,其中隐藏层得到输入经由激活函数再进行输出,在这个神经网络中,隐藏层的每一个神经元都由全部输入数据进行输入,再由隐藏中的W,B权重相乘与相加,最后经由激活函数进行输出,我们也可以通过加入多个隐藏层来构建一个更加深的神经网络。
神经网络模型的训练
神经网络的模型训练,通常由以下几步来完成。
定义和初始化模型
首先需要对于神经网络的结构进行定义,几层隐藏层,中间使用什么层作为隐藏层,初始化模型即需要对于模型的参数权重进行初始化。
定义损失函数
损失函数通常为模型的预测值Y与实际的Y之间的差值。预测值Y为对于输入X,通过模型的运算得出的值称之为预测Y。比较常见的损失函数为
其中为模型预测后得出的值,通过优化损失函数使得模型预测的值与实际的值进行最小化。
定义优化函数
优化函数是指定义算法使得最小化损失函数,比较常见的优化算法有梯度下降算法、批量梯度下降算法、动量梯度下降算法、Adam算法等。以梯度下降为例,有算法如下:
我们有在神经网络中的权重参数矩阵有 。
Repeat until convergence{
}
其中a为学习率,这是一个超参数,通过调节来指定在梯度下降的过程中进行下降的速度,而 为上式中损失函数的求导数。
假设我们设在神经网络中只有一个权重参数,则我们有梯度下降算法
Repeat until convergence{
}
则上面的下降算法则在作如下变化,如图4如示:
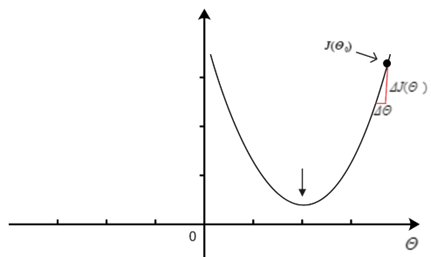
当我们的参数在最小值的右边时,由于其导数为的与的比值,当增量足够小时,则有,所以当执行算法
时参数会逐渐减小,并沿着横坐标往左向着最小值的方向进行逼进,如图5所示。
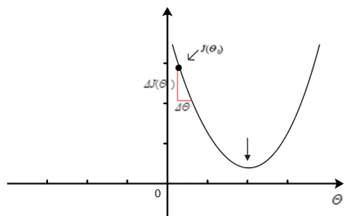
当我们的参数在最小值的左边时,由于其 为负,会导致整体算法在运算时时会逐渐变大,并沿着横坐标往右向着最小值的方向进行逼进。
而当我们把超参数a设置过大时,会导致参数在最小值的最大距离之间来回振荡,而当超参数设置过小会导致迭代次数的增加。以上为神经网络中只有一个权重参数进行下降算法时的过程,而把这个参数从一维推广到多维可以得到类似的下降过程。
模型训练
我们在对模型进行计算与训练时,会进行两次传播,即正向传播与反向传播,其中正向传播为整个模型的计算过程。如图6所示。
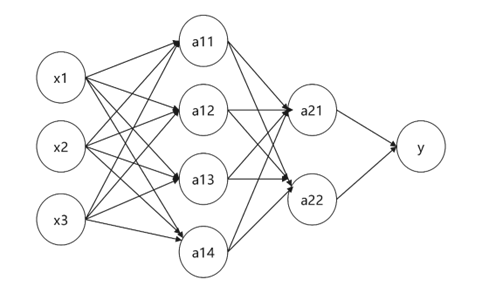
正向传播通过从左往后进行计算,得到各个节点的值并逐步向右进行传播,最终到输出层得到最后的预测值Y,而反向传播的过程与正向传播正相反,是从右往左进行传播并逐步计算出各个节点的值,最终到输入层。
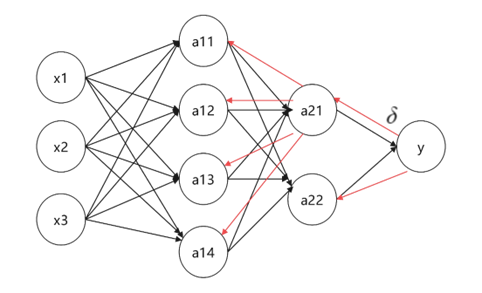
如图7所示,其中为节点之间的误差,而执行反向传播的意义是为计算各参数的导数所需的数据,即优化算法需要各参数的导数,而导数需要进行正向传播与反向传播计算出各个节点的值与误差。
模型训练需要用到损失函数的定义,优化算法的定义,以及模型和迭代次数等参数。其中模型训练的流程如图8所示。
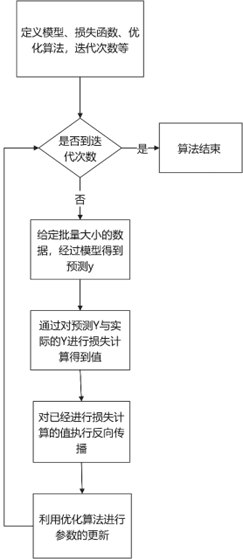
我们在进行模型训练时经过模型的计算得到的预测Y,并通过损失函数来进行两者数据之间的差值,再执行反向传播,并利用优化算法对参数进行更新,如此反复,直到整个迭代过程结束。
卷积神经网络
卷积神经网络简介
卷积神经网络开始主要是应用于图像,因为卷积神经网络在图像中具有高效、快速提取的特性,故而在图像处理中有着较为广泛的应用。这是因为卷积神经网络主要有两个特性,一为局部感知,二为权重共享。对于神经元来说,无需全部感知,只需要局部感知即可。其中局部感知主要是进行局部区域信息的提取,通过一个个的过滤器进行参数的计算,权重共享是指过滤器在进行信息的提取时,会共用一个参数来进行计算值,这使得参数大大减少,会让训练更加高效。
其中卷积神经网络的计算过程如下图9所示。
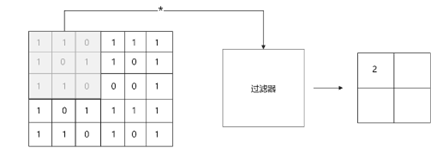
上图为一个过滤器通过卷积操作进行局部信息的提取并进行计算的过程,在这过程之后,窗口会继续进行滑动去提取未进行过滤器提取的信息。
池化层,对于不同的特征进行简化操作,一为可以进行神经元大小的缩减,二为可以提取主要特征,而忽略其次要特征,这使得我们的神经网络可以减少参数,使得训练的速度更快,也可以大幅度减少欠拟合的情况。
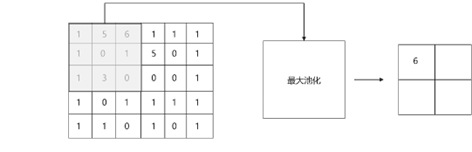
其中池化层有两种操作,一为最大池化层,二为平均池化层,其中最大池层是指所在的窗口范围内进行最大特征的提取,而忽略其它特征,而平均池化层是指在窗口范围内进行信息的值相加并取平均化。其中最大池化进行信息提取的过程如图10所示。
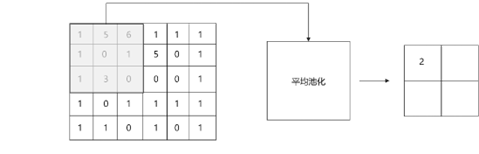
而平均池化层进行信息提取,如图11所示。
卷积神经网络在文本上的应用
卷积神经网络在开始是用于处理图像信息,如对图像进行特征的提取。其中把卷积神经网络应用于文本的开创性的模型是textCNN模型,该模型主要是通过卷积神经网络进行文本信息的提取,进行得到一个文本感情分类的模型。后面卷积神经网络也开始应用于文本的处理中,其中由Baotian Hu等人提出的自然语言句子匹配的卷积神经网络架构,他们提出了一个自然语言的文本匹配模型。如图12所示
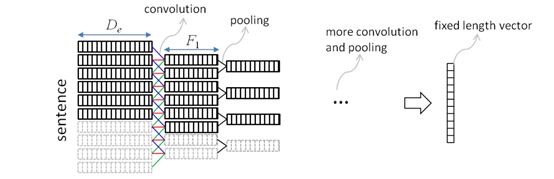
该模型是把文本输入进嵌入层,获取各个词的嵌入向量,再通过滑动窗口进行卷积,再通过池化层进行大小与的缩减与有效信息特征的提取,如此往复直到模型把文本缩减到一个只有固定大小的向量。
其中BaotianHu等人在论文中提到的一个关于在滑动窗口中卷积的例子是如图13如示。
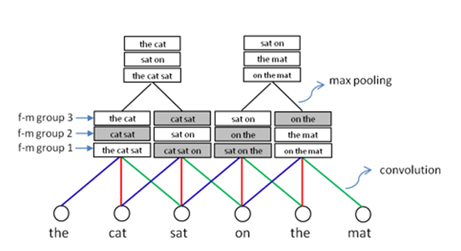
例子中通过卷积单元在三字窗口中关注不同的片段,给出了不同的组合,同时对于可信度较低的组合标记为灰色,然后用池化在两个窗口之间进行滑动,选取可信度较高的组合,排除可信度最低的组合,使得信息可以更加有效的提取。
BaotianHu等人在论文中提出一种用于两个句子之间进行匹配的模型如图14所示
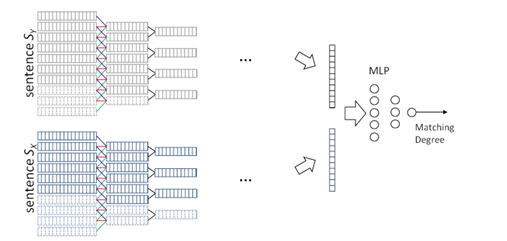
可以看出这个模型是两个句子通过反复卷积、池化之后,把向量缩减到一个固定大小再通过多层感知器进行匹配程序的输出。
基于CNN的代码查重系统的模型设计
代码文本预处理
我们对于表1中所列出的代码抄袭手段进行相应的处理,即对于代码文本加注释、给代码文本加空格、数据类型变化,以及对变量名进行更改进行如下处理。
1) 我们对代码文本进行注释的删除,空格和头文件的去除。
2) 对于变量名进行风格的统一,统一用var字符来进行表示。
3) 为了应对数据类型的变化,我们对于数据类型我们也进行统一的数据类型字符来进行代替,用data_type来进行数据类的替代。
4) 为了应对循环结构的变化,我们对于循环结构进行风格的统一,对于所有的循环类型,统一用while来进行代替。
5) 为了应对变量声明的变化,我们对于变量的声明也作统一的变化,如把 int a,b=10; 变化为 int a;int b;b=10;
6) 我们把数字与字符也作变化,把数字变成统一的文本NUMS,把字符变作WORDS。
对于上述内容的总结,我们有如下表
| 编号 | 代码内容 | 替换标记 |
|---|---|---|
| 1 | 变量名 | var |
| 2 | 数据类型 | data_type |
| 3 | 循环 | while |
| 4 | 数字 | nums |
| 5 | 字符 | words |
| 6 | 函数声明的函数名 | func_declar |
| 7 | 函数调用 | call_func |
数据的处理与采样
首先通过把相关的数据进行保留其有效数据,并把数据源划分为三类,分别为源代码、正例、负例。其中正例为对于源代码进行位置交换、变量名的更改、循环语句关键字的改变、函数的合并与切割,变量声明的改变等一系仿抄袭手段的变换。负例则是与源代码完全不同的代码文本,如我们有源代码1_source,通过抄袭手段变换得到正例1_positive,我们把2_source设置为1_negative表示为源代码1_source的负例。即我们得到三个不同的数据集,分别为源代码数据集、正例数据集和负例数据集。接下来我们通过应用表1中的规则对三个数据集都进行代码预处理操作。
基于CNN的代码查重模型
我们对于代码文本进行预处理之后,我们需要对于预处理之后的代码文本进行查重操作。考虑利用卷积神经网络的高效提取手段来进行代码文本的处理。我们利用Baotian Hu等人提出的自然语言句子匹配的卷积神经网络架构的模型来进行代码查重操作。
我们有基于CNN的代码查重训练模型如图15所示
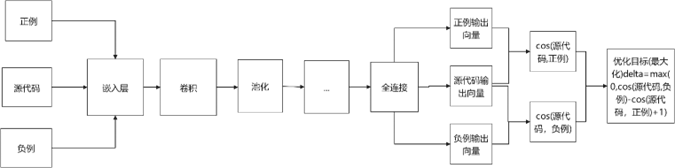
我们对于文本代码采用(正例,源代码,负例)的形式进行输入,首先经由嵌入层由文字变化为向量,再经过三层卷积和池化操作,使得有效信息被提取,以及减少了无效信息,最后进行一层全连接层的语义连接,再对得到的向量进行cos函数的比较,再对目标函数进行相应的优化。
卷积层:对于卷积我们在经过嵌入层的代码转换的矩阵中,进行窗口的滑动操作并进行卷积操作,我们对于代码文本的卷积有如下定义。
其中表a层数,而f则为特征映射的卷积单元。
这部分为连接来自句子输入x的k1(滑动窗口的宽度)单词的向量。
最大池化层:在每次卷积之后,我们在每两个单元窗口中为之间过滤器取一个最大池化操作。这里的池化操作有两重效果:一则可以将前层的特性大小缩小一半,从而可以快速对句子进行差异化吸收。二则可以过滤掉一些可信度较低的句子组合。
其中cos函数为
我们有最大优化目标为
通过上述一系列的特征提取与相似函数计算,到最后得到模型预测的值,再经过反向传播与梯度下降操作,使得变得逐渐收敛。
我们通过已经训练完毕的模型进行代码的查重与对比,对于此我们有代码对比查重模型,如图16所示。
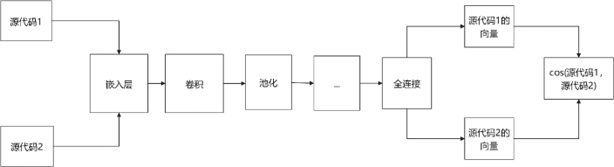
通过在训练模型中已经更新完成的各层参数来进行代码对比的运算,源代码1和源代码2通过查重模型得到各自的向量,并通过cos来进行代码查重的概率计算。
通过该模型进行数据的训练以及超参数的调整可以使得模型去学习抄袭手段,通过数据的学习去对抗新的作弊方式。