基础类
指针与引用的区别
引用与指针的关系,引用需要一开始就要指定值,不可能用空,而指针可以初始为空。

不要对数组使用多态
有代码
1 | class BST{ ...}; |
当给函数传递一个含有BST对象的数组变量,则它正常运行
1 | BST BSTArray[10]; |
当把BalancedBST对象的数组变量传递给printBSTArray函数时,会产生什么样的后果
1 | BalancedBST bBSTArray[10]; |
我们有函数循环
1 | for(int i=0;i<numElements;){ |
这里的array[i]只是一个指针算法的缩写:它所代表的是*(array)。我们知道array是一个指向数组起始地址的指针,但是array中各元素内存地址与数组的起始地址的间隔究竟有多大呢?
但是因为我们BalancedBST与BST的内存大小不一致,会导致array[i]以BST的地址空间去BalancedBST类型。
运算符
需要谨慎的定义类型转换函数
C++编译器能够在两种数据类型之间进行隐式转换。有两种函数允许编译器进行这些转换:半参数构造函数和隐式类型转换运算符。单参数构造函数是指只用一个参数即可以调用的构造函数。

为了允许Rational(有理数)类隐式转换为double类型,可以如此声明Rational类。


解决方法是用不使用语法关键字的等同的函数来替代转换运算符。例如为了把Rational对象转换为double,用asDouble函数代替operator double函数:

理解各种不同的含义的new和delete

operator new所了解的内存分配。把operator new返回的未经处理的指针传递给一个对象是new操作符的工作。当你的编译器遇到这样的语句
1 | string*ps=new string("Memory Management"); |
它生成的代码或多或少与下面代码相似
1 | void *memory=opeator new(sizeof(string));//得到未经处理的内存,为String对象 |
注意第二步包含了构造函数的调用,做为一个程序员被禁止这样去做。你的编译器没有这个约束,可以做它想做的一切。因此如果你想建立一个堆对象就必须用new操作会,不能直接调用构造函数来初始化对象。
placement new

Deletion and Memory Deallocation
为了避免内存泄漏,每个动态内存分配必须与一个等同相反的deallocation 对应。
1 | string*ps; |
编译器会生成代码来析构对象并释放对象占有的内存。
Operator delete 用来释放内存,它被这样声明。
1 | void operator delete(void *memoryToBeBeallocated); |
因此
1 | delete ps; |
导致编译器生成类似于这样的代码
1 | ps->~string(); //call the object's dtor |
这里有一个隐含的意思是如果你只想处理未被初始化的内存,应该绕过new和delete 操作符,而调用operator new 获得内存和operator delete释放内存给系统。
1 | void *buffer=operator new(50*sizeof(char)); |

Arrays
1 | string*ps=new string[10]; |
第一内存不再用operator new 分配,代替以等同的数组分配函数,叫做 operator new[]。
第二不同是new操作符调用构造函数的数量。对于数组,在数组中每一个对象的构造函数都必须被调用
1 | string*ps= new string[10]; |
同样当delete操作符用于数组时,它为每个数组元素调用析构函数,然后调用operator delete 来释放内存。
异常
使用析构函数防止资源泄漏
我们有代码
1 | class ALA{ |
这个函数循环遍历dataSource内的信息,处理它所遇到的每个项目。但需要注意的是在每次循环结尾处删除pas,因为每次调用readALA都建立一个堆对象,如果不删除对象,循环将产生资源泄露。
现在考虑一下,如果 pa->processAdoption 抛出了一个异常,将会发生什么?processAdoptions 没有捕获异常, 所以异常将传递给 processAdoptions 的调用者。 传递中,processAdoptions 函数中的调用 pa->processAdoption 语句后的所有语句都被跳过,这就是说 pa 没有被删除。结果,任何时候 pa->processAdoption 抛出一个异常都会导致processAdoptions 内存泄漏。


我们需要用一个对象存储需要被自动释放的资源 ,然后依靠对象
的析构函数来释放资源。


在构造函数中防止资源泄漏


但是有一个问题是,因我们在构造函数执行中,一个异常被抛出,会发生什么问题
1 | if(audioClipFileName!=""){ |

所以我们需要在构造函数中也要对异常进行处理。

理解“抛出一个异常”与”传递一个参数”或”调用一个虚函数”之间的差异
从语法上来看抛出一个异常与传递一个参数两者基本相同,即传递函数参数与异常的途径可以是传值、传递引用或者传递指针。但是产生差异的原因是:当调用函数时,这个程序的控制权最终还是会返回到函数的调用处,但是当抛出一个异常时,控制权永远不会回到抛出异常的地方。
1 | // 一个函数,从流中读值到Widget中istream operator>>(istream& s, Widget& w);void passAndThrowWidget() |
1 | // 一个函数,从流中读值到Widget中istream operator>>(istream& s, Widget& w);void passAndThrowWidget() |
当传递localWidget到函数operator>>里,不用进行拷贝操作,而是把 operator>>内的引用类型变量 w 指向 localWidget,任何对 w 的操作实际上都施加到 localWidget 上。这与抛出 localWidget 异常有很大不同。 不论通过传值捕获异常还是通过引用捕获(不能通过指针捕获这个异常, 因为类型不匹配)都将进行 lcalWidget 的拷贝操作, 也就说传递到 catch子句中的是 localWidget 的拷贝。必须这么做,因为当 localWidget 离开了生存空间后,其析构函数将被调用 。

当抛出异常时仍将复制出localWidget的一个拷贝。这表示即使通过引用来捕获异常,也不能在catch块中修改localWidget;仅仅能修改localWidget的拷贝。对异常对象进行强制复制拷贝,这个限制有助于我们理解参数传递与抛出异常的第二个差异:抛出异常运行速度比参数传递要慢。
当异常对象被拷贝时,拷贝操作是由对象的拷贝构造函数完成的。该拷贝构造函数是对象的静态类型(static type)所对应类的拷贝构造函数,而不是对象的动态类型(dynamictype)对应类的拷贝构造函数。

这里抛出的异常对象是Widget,即使rw引用的是一个SpecialWidget。因为rw的静态类型(statictype)是Widget,而不是SpecialWidget。你的编译器根本没有注意到rw引用的是一个SpecialWidget。

传递参数和传递异常最后一点差别是catch子句匹配顺序总是取决于它们在程序中出现的顺序。因此一个派生类异常可能被处理其基类异常的 catch 子句捕获,即使同时存在有能直接处理该派生类异常的 catch 子句,与相同的 try 块相对应。

当你调用一个虚拟函数时,被调用的函数位于与发出函数调用的对象的动态类型(dynamic type)最相近的类里。你可以这样说虚拟函数采用最优适合法,而异常处理采用的是最先适合法。如果一个处理派生类异常的catch子句位于处理基类异常的catch子句后面,编译器会发出警告。(因为这样的代码在C++里通常是不合法的。)不过你最好做好预先防范:不要把处理基类异常的catch子句放在处理派生类异常的catch子句的前面。
意思是当有父类与派生类所采用指针进行抛出异常时,若把处理派生类的异常catch子句处于处理基类异常的catch子句后面,会造成所有派生类的指针都进行处理基类的catch子句里面。
综上所述,把一个对象传递给函数或一个对象调用虚拟函数与把一个对象做为异常抛出,这之间有三个主要区别。第一、异常对象在传递时总被进行拷贝;当通过传值方式捕获时,异常对象被拷贝了两次。对象做为参数传递给函数时不一定需要被拷贝。第二、对象做为异常被抛出与做为参数传递给函数相比,前者类型转换比后者要少(前者只有两种转换形式)。最后一点,catch 子句进行异常类型匹配的顺序是它们在源代码中出现的顺序,第一
个类型匹配成功的 catch 将被用来执行。当一个对象调用一个虚拟函数时,被选择的函数位于与对象类型匹配最佳的类里,即使该类不是在源代码的最前头
尽量使用引用捕获
因为当使用指针进行捕获里会出现父类与派生类的问题以及传进来的值进行如何维护的问题,而若采用值捕获里,可能会出现 slice 问题,只有使用引用捕获才可以正确的执行。
效率
考虑使用LAZY EVALUATION(懒惰计算法)
引用计数

通常string拷贝构造函数让s2被s1初始化后,s1和s2都有自己的”Hello”拷贝。这种拷贝构造函数会引起较大的开销,因为要制作s1值的拷贝,并把值赋给s2,这通常需要用new操作符分配堆内存(参见条款8),需要调用strcpy函数拷贝s1内的数据到s2。这是一个eager evaluation(热情计算):只因为到string拷贝构造函数,就要制作s1值的拷贝并把它赋给s2。然而这时的s2并不需要这个值的拷贝,因为s2没有被使用。
懒惰计算是指当有一个元素去赋值给另一元素时,若是只是只读的话可以暂时让两个元素使用同一地址,当有元素改变地址里面的值时就再开辟一个新地址,再把值复制过去,有点像操作系统里面内存管理的写时复制。
- 区别对待读取和写入
我们有代码

首先调用 operator[]用来读取 string 的部分值,但是第二次调用该函数是为了完成写操作。我们应能够区别对待读调用和写调用,因为读取 reference-counted string 是很容易的,而写入这个 string 则需要在写入前对该 string 值制作一个新拷贝。
这样做则需到了困难,因为operator[]无法识别context是读取操作和写操作,无法去区别这两者操作。
- Lazy Fetching(懒惰提取)
第三个lazy evaluation的例子,假设你的程序使用了一些包含许多字段的大型对象。这些对象的生存期超越了程序运行期,所以它们必须被存储在数据库里。每一个对都有一个唯一的对象标识符,用来从数据库中重新获得对象:

因为LargeObject对象实例很大,为这样的对象获取所有的数据,数据库的操作的开销将非常大,特别是如果从远程数据库中获取数据和通过网络发送数据时。而在这种情况下,不需要读去所有数据。

这里仅仅需要 filed2 的值,所以为获取其它字段而付出的努力都是浪费。 当 LargeObject 对象被建立时,不从磁盘上读取所有的数据,这样懒惰法解决了这个问题。不过这时建立的仅是一个对象“壳”,当需要某个数据时,这个数据才被从数据库中取回。
- Lazy Expression Evaluation(懒惰表达式计算)

通常 operator 的实现使用 eagar evaluation:在这种情况下,它会计算和返回 m1 与m2 的和。这个计算量相当大(1000000 次加法运算),当然系统也会分配内存来存储这些值。lazy evaluation 方法说这样做工作太多,所以还是不要去做。而是应该建立一个数据结构来表示 m3 的值是 m1 与 m2 的和,在用一个 enum 表示它们间是加法操作。很明显,建立这个数据结构比 m1 与 m2 相加要快许多,也能够节省大量的内存。

理解临时对象的来源

真正的临时对象是由编译产生的,而不是由程序员自己写的。首先考虑为使函数成功调用而建立临时对象这种情况。 当传送给函数的对象类型与参数类型不匹配时会产生这种情况。 例如一个函数, 它用来计算一个字符在字符串中出现的次数:

看一下 countChar 的调用。第一个被传送的参数是字符数组,但是对应函数的正被绑定的参数的类型是 const string&。 但是由于我们传递的是char数组对象,C++编译器会把buffer隐式转换成string,然后再进行调用。
建立临时对象的第二种环境是函数返回对象时。例如 operator+必须返回一个对象,以表示它的两个操作数的和(参见 Effective C++ 条款 23)。例如给定一个类型 Number,这种类型的 operator+被这样声明:
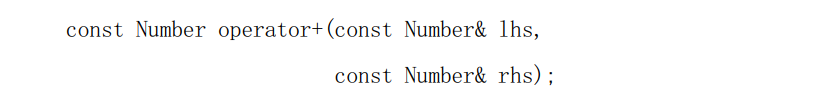
这个函数的返回值是临时的,因为它没有被命名;它只是函数的返回值。你必须为每次调用 operator+构造和释放这个对象而付出代价。 两个Number相加之后,会返回一个由两个对象相加后的新对象结果。
协助完成返回值优化


通过上述代码进行返回对象,编译器可能会进行优化,使得不会进行拷贝。
考虑用运算符的赋值形式取代其单独形式

理解虚拟函数、多继承、虚基类和RTT1所需的代价
当调用一个虚拟函数时,被执行的代码必须与调用函数的对象的动态类型相一致,指向对象的指针与引用的类型是不重要的。
一个vtbl通常是一个函数指针数组(一些编译器使用链表来代替数组)在程序中的每个类只要声明了虚函数或继承了虚函数,它就有自己的vtal,并且类中vtbl的项目是指向虚函数实现体的指针。
1 | class C1{ |
C1的virtual table数组看起来如下图所示:

如果有一个C2类继承自C1,重新定义了它继承的一些虚函数,并加入它自己的一此虚函数:
1 | class C2:public C1{ |


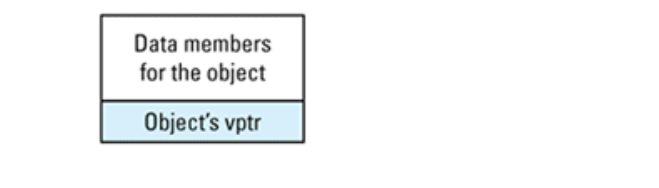
Virtual table 只实现了虚拟函数的一半机制,如果只有这些是没有用的。只有用某种方法指出每个对象对应的 vtbl 时,它们才能使用。这是 virtual table pointer 的工作,它来建立这种联系。每个声明了虚函数的对象都带有它,它是一个看不见的数据成员,指向对应类的virtual table。这个看不见的数据成员也称为 vptr,被编译器加在对象里,位置只有才编译器知道。从理论上讲,我们可以认为包含有虚函数的对象的布局是这样的:
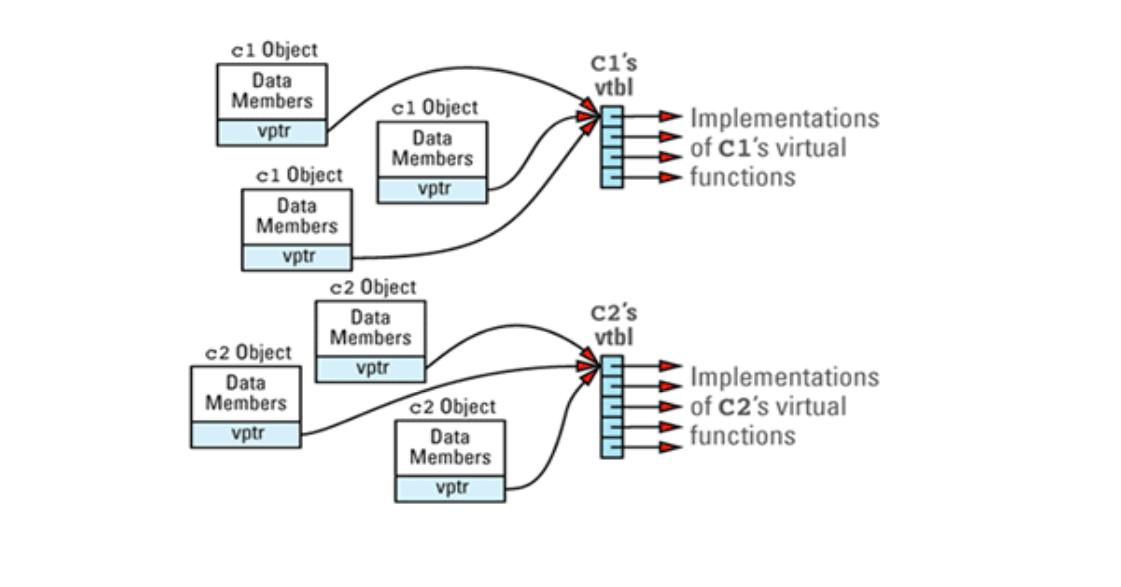
假如我们有一个程序,包含几个 C1 和 C2 对象。对象、vptr 和刚才我们讲述的 vtbl之间的关系,在程序里我们可以这样去想象:
1 | //考虑这段程序代码 |
通过指针 pC1 调用虚拟函数 f1。仅仅看这段代码,你不会知道它调用的是那一个 f1函数――C1::f1 或 C2::f1,因为 pC1 可以指向 C1 对象也可以指向 C2 对象。尽管如此编译器仍然得为在 makeACall 的 f1 函数的调用生成代码,它必须确保无论 pC1 指向什么对象,函数的调用必须正确。编译器生成的代码会做如下这些事情:
1. 通过对象的 vptr 找到类的 vtbl。这是一个简单的操作,因为编译器知道在对象内哪里能找到 vptr(毕竟是由编译器放置的它们)。因此这个代价只是一个偏移调整(以得到vptr)和一个指针的间接寻址(以得到 vtbl)。
2. 找到对应 vtbl 内的指向被调用函数的指针(在上例中是 f1)。这也是很简单的,因为编译器为每个虚函数在 vtbl 内分配了一个唯一的索引。 这步的代价只是在 vtbl 数组内的一个偏移。
3. 调用第二步找到的的指针所指向的函数。
假设我们每个对象有一个隐藏的数据叫做vptr,而且f1在vtbl中索引为i,则此语句。
1 | pC1->f1(); |
考虑如下多继承
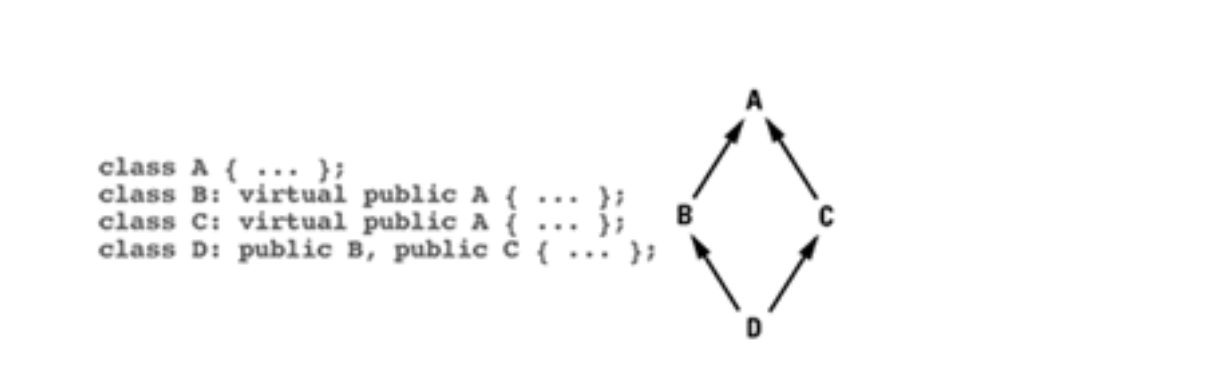
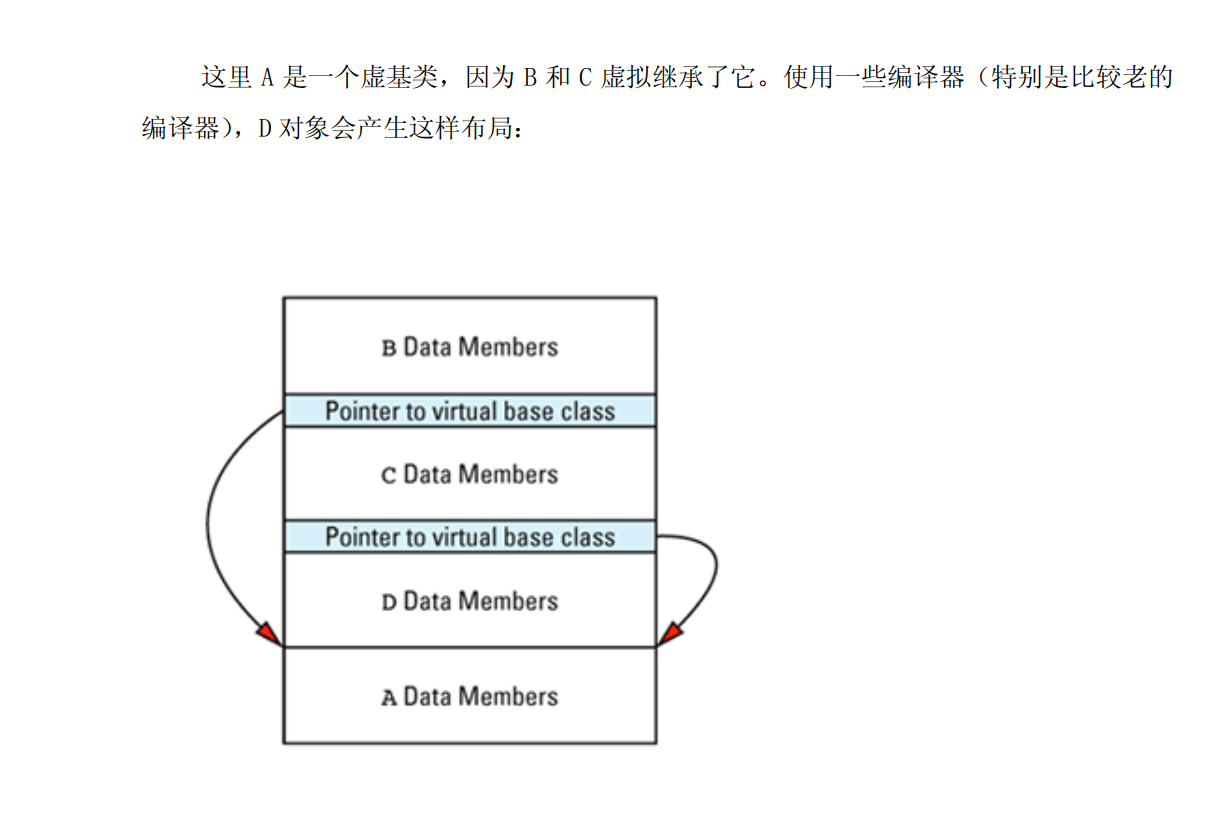
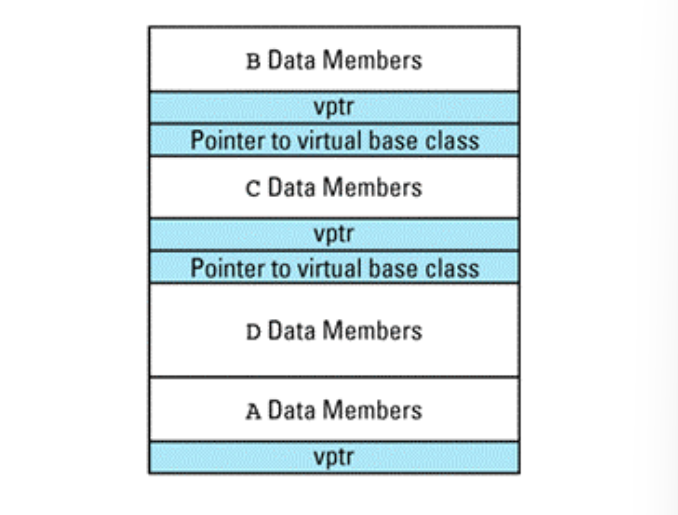
把vptr指针加入图中就有,
RTTI 能让我们在运行时找到对象和类的有关信息,所以肯定有某个地方存储了这些信息让我们查询。这些信息被存储在类型为 type_info 的对象里,你能通过使用 typeid 操作符访问一个类的 type_info 对象。
例如, vtbl 数组的索引 0 处可以包含一个 type_info 对象的指针, 这个对象属于该 vtbl相对应的类。上述 C1 类的 vtbl 看上去象这样:

技巧
将构造函数和非成员函数虚拟化
- 虚拟构造函数
我们有类
1 | class NLComponet{ //用于newsletter componets |
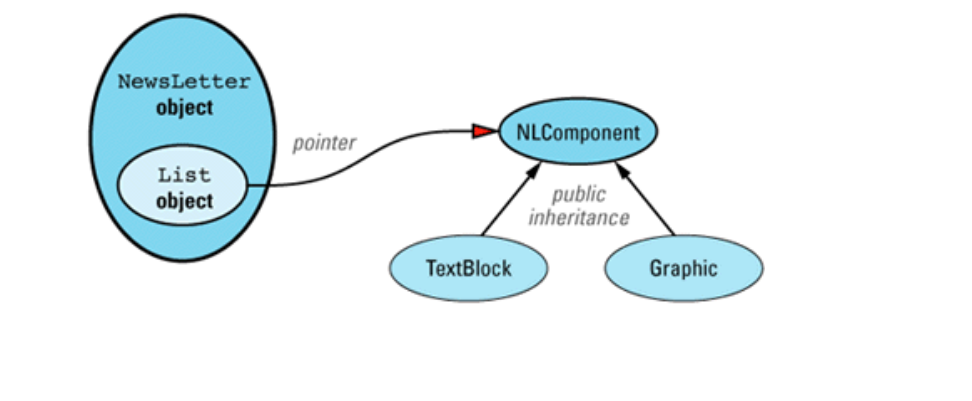

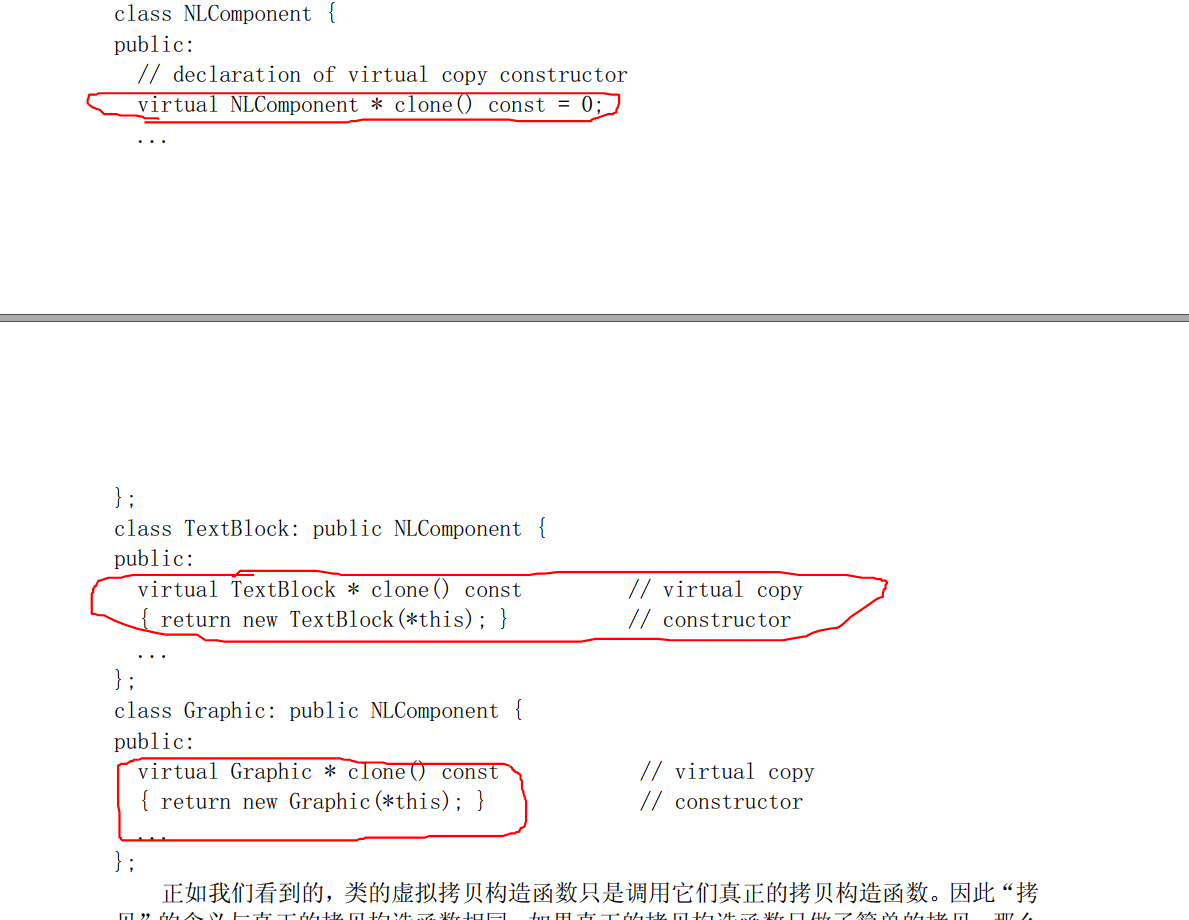
考虑一下 readComponent 所做的工作。它根据所读取的数据建立了一个新对象,或是TextBlock 或是 Graphic。因为它能建立新对象,它的行为与构造函数相似,而且因为它能建立不同类型的对象,我们称它为虚拟构造函数。虚拟构造函数是指能够根据输入给它的数据的不同而建立不同类型的对象。
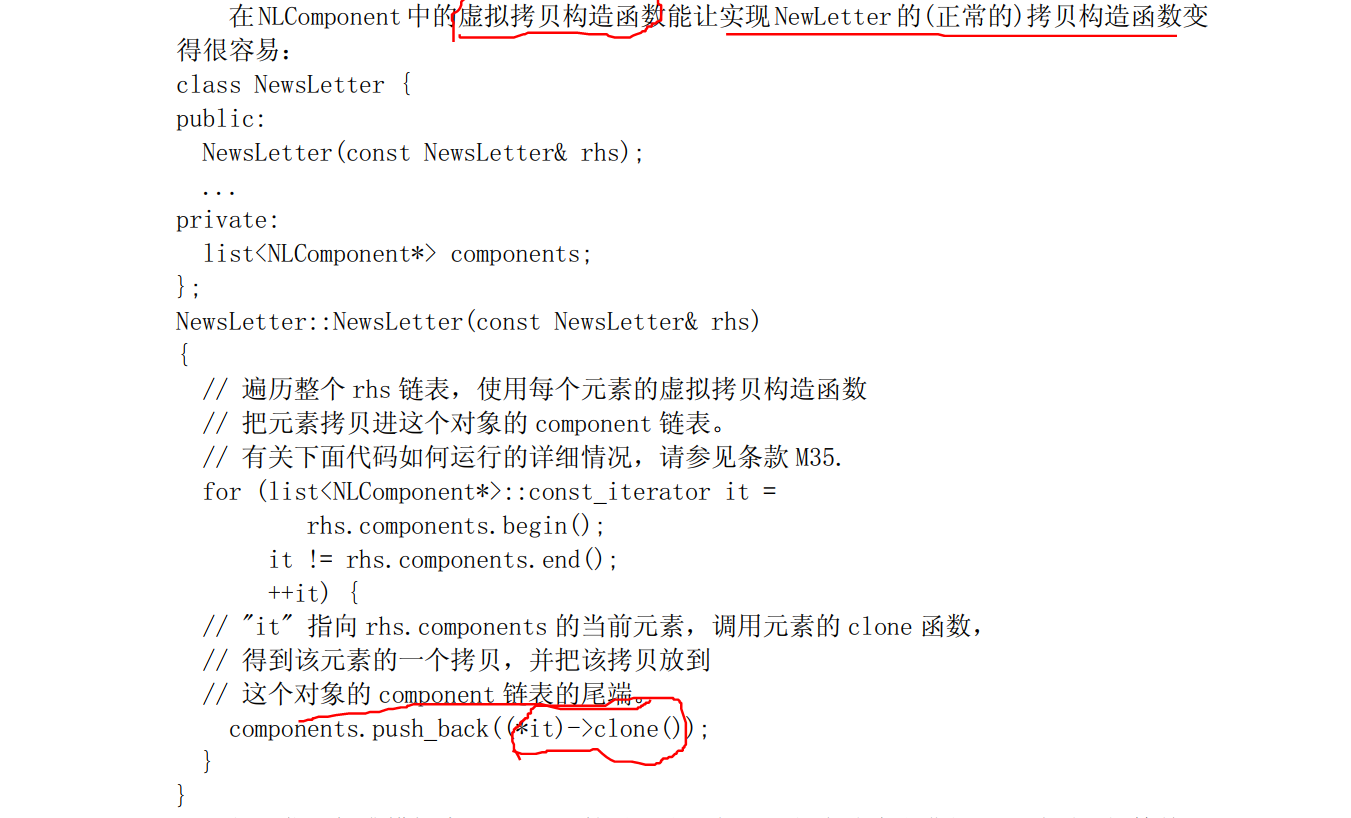
- 虚拟拷贝构造函数
虚拟
拷贝构造函数能返回一个指针,指向调用该函数的对象的新拷贝。因为这种行为特性,虚拟拷贝构造函数的名字一般都是 copySelf,cloneSelf 或者是象下面这样就叫做 clone。很少会有函数能以这么直接的方式实现它:
要求或禁止在堆中产生对象
- 要求在堆中建立对象
你必须找到一种方法禁止以调用“new”以外的其它手段建立对象。

我们把析构函数进行隐藏,使得变量在栈中建立。另一种方法是把构造函数进行隐藏。

- 判断一个对象是否在堆中
我们有以下代码
1 | NonNegativeUPNumber *n1 = |
对于NonNegativeNPNumber构造函数无法区分出新建的对象是在堆中还是在栈中。